TR2022-022
The Cocktail Fork Problem: Three-Stem Audio Separation for Real-World Soundtracks
-
- , "The Cocktail Fork Problem: Three-Stem Audio Separation for Real-World Soundtracks", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), DOI: 10.1109/ICASSP43922.2022.9746005, April 2022, pp. 526-530.BibTeX TR2022-022 PDF Video Data Software
- @inproceedings{Petermann2022apr,
- author = {Petermann, Darius and Wichern, Gordon and Wang, Zhong-Qiu and {Le Roux}, Jonathan},
- title = {{The Cocktail Fork Problem: Three-Stem Audio Separation for Real-World Soundtracks}},
- booktitle = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
- year = 2022,
- pages = {526--530},
- month = apr,
- doi = {10.1109/ICASSP43922.2022.9746005},
- url = {https://www.merl.com/publications/TR2022-022}
- }
- , "The Cocktail Fork Problem: Three-Stem Audio Separation for Real-World Soundtracks", IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), DOI: 10.1109/ICASSP43922.2022.9746005, April 2022, pp. 526-530.
-
MERL Contacts:
-
Research Areas:


Abstract:
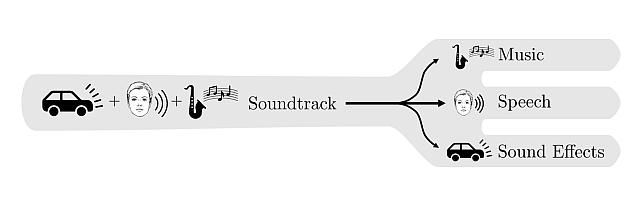
The cocktail party problem aims at isolating any source of interest within a complex acoustic scene, and has long inspired audio source separation research. Recent efforts have mainly focused on separating speech from noise, speech from speech, musical instruments from each other, or sound events from each other. However, separating an audio mixture (e.g., movie soundtrack) into the three broad categories of speech, music, and sound effects (understood to include ambient noise and natural sound events) has been left largely unexplored, despite a wide range of potential applications. This paper formalizes this task as the cocktail fork problem, and presents the Divide and Remaster (DnR) dataset to foster research on this topic. DnR is built from three well-established audio datasets (LibriSpeech, FMA, FSD50k), taking care to reproduce conditions similar to professionally produced content in terms of source overlap and relative loudness, and made available at CD quality. We benchmark standard source separation algorithms on DnR, and further introduce a new multi-resolution model to better address the variety of acoustic characteristics of the three source types. Our best model produces SI-SDR improvements over the mixture of 11.0 dB for music, 11.2 dB for speech, and 10.8 dB for sound effects.
Software & Data Downloads
Related News & Events
-
NEWS MERL co-organizes the 2023 Sound Demixing (SDX2023) Challenge and Workshop Date: January 23, 2023 - November 4, 2023
Where: International Symposium of Music Information Retrieval (ISMR)
MERL Contacts: Jonathan Le Roux; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL Speech & Audio team members Gordon Wichern and Jonathan Le Roux co-organized the 2023 Sound Demixing Challenge along with researchers from Sony, Moises AI, Audioshake, and Meta.
The SDX2023 Challenge was hosted on the AI Crowd platform and had a prize pool of $42,000 distributed to the winning teams across two tracks: Music Demixing and Cinematic Sound Demixing. A unique aspect of this challenge was the ability to test the audio source separation models developed by challenge participants on non-public songs from Sony Music Entertainment Japan for the music demixing track, and movie soundtracks from Sony Pictures for the cinematic sound demixing track. The challenge ran from January 23rd to May 1st, 2023, and had 884 participants distributed across 68 teams submitting 2828 source separation models. The winners will be announced at the SDX2023 Workshop, which will take place as a satellite event at the International Symposium of Music Information Retrieval (ISMR) in Milan, Italy on November 4, 2023.
MERL’s contribution to SDX2023 focused mainly on the cinematic demixing track. In addition to sponsoring the prizes awarded to the winning teams for that track, the baseline system and initial training data were MERL’s Cocktail Fork separation model and Divide and Remaster dataset, respectively. MERL researchers also contributed to a Town Hall kicking off the challenge, co-authored a scientific paper describing the challenge outcomes, and co-organized the SDX2023 Workshop.
- MERL Speech & Audio team members Gordon Wichern and Jonathan Le Roux co-organized the 2023 Sound Demixing Challenge along with researchers from Sony, Moises AI, Audioshake, and Meta.
-
NEWS Jonathan Le Roux gives invited talk at CMU's Language Technology Institute Colloquium Date: December 9, 2022
Where: Pittsburg, PA
MERL Contact: Jonathan Le Roux
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL Senior Principal Research Scientist and Speech and Audio Senior Team Leader, Jonathan Le Roux, was invited by Carnegie Mellon University's Language Technology Institute (LTI) to give an invited talk as part of the LTI Colloquium Series. The LTI Colloquium is a prestigious series of talks given by experts from across the country related to different areas of language technologies. Jonathan's talk, entitled "Towards general and flexible audio source separation", presented an overview of techniques developed at MERL towards the goal of robustly and flexibly decomposing and analyzing an acoustic scene, describing in particular the Speech and Audio Team's efforts to extend MERL's early speech separation and enhancement methods to more challenging environments, and to more general and less supervised scenarios.
-
NEWS MERL presenting 8 papers at ICASSP 2022 Date: May 22, 2022 - May 27, 2022
Where: Singapore
MERL Contacts: Anoop Cherian; Chiori Hori; Toshiaki Koike-Akino; Jonathan Le Roux; Tim K. Marks; Philip V. Orlik; Kuan-Chuan Peng; Pu (Perry) Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Computer Vision, Signal Processing, Speech & AudioBrief- MERL researchers are presenting 8 papers at the IEEE International Conference on Acoustics, Speech & Signal Processing (ICASSP), which is being held in Singapore from May 22-27, 2022. A week of virtual presentations also took place earlier this month.
Topics to be presented include recent advances in speech recognition, audio processing, scene understanding, computational sensing, and classification.
ICASSP is the flagship conference of the IEEE Signal Processing Society, and the world's largest and most comprehensive technical conference focused on the research advances and latest technological development in signal and information processing. The event attracts more than 2000 participants each year.
- MERL researchers are presenting 8 papers at the IEEE International Conference on Acoustics, Speech & Signal Processing (ICASSP), which is being held in Singapore from May 22-27, 2022. A week of virtual presentations also took place earlier this month.
Related Video
Related Publication
- @article{Petermann2021oct,
- author = {Petermann, Darius and Wichern, Gordon and Wang, Zhong-Qiu and {Le Roux}, Jonathan},
- title = {{The Cocktail Fork Problem: Three-Stem Audio Separation for Real-World Soundtracks}},
- journal = {arXiv},
- year = 2021,
- month = oct,
- url = {https://arxiv.org/abs/2110.09958}
- }