Gordon Wichern

- Phone: 617-621-7574
- Email:
-
Position:
Research / Technical Staff
Lead Research Scientist -
Education:
Ph.D., Arizona State University, 2010 -
Research Areas:
External Links:
Gordon's Quick Links
-
Biography
Gordon's research interests are at the intersection of signal processing and machine learning applied to speech, music, and environmental sounds. Prior to joining MERL, Gordon worked at iZotope inc. developing audio signal processing software, and at MIT Lincoln Laboratory where he worked in radar target tracking.
-
Recent News & Events
-
NEWS MERL Presents 4 Main Conference Papers and 6 Workshop Papers at ICML 2026 Date: July 6, 2026 - July 11, 2026
Where: COEX, Seoul, South Korea
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Stefano Di Cairano; Toshiaki Koike-Akino; Christopher R. Laughman; Jing Liu; Suhas Lohit; Kuan-Chuan Peng; Alexander Schperberg; Ye Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Computer Vision, Machine Learning, Signal ProcessingBrief- MERL researchers are proud to present 4 main conference papers and 6 workshop papers at ICML 2026. ICML, taking place from July 6-11 in Seoul, South Korea, is a premier international conference in machine learning.
Main Conference Papers with MERL Authors:
1. Understanding Dynamic Compute Allocation in Recurrent Transformers by Ibraheem Muhammad Moosa, Suhas Lohit, Ye Wang, Moitreya Chatterjee, and Wenpeng Yin.
2. LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior by Qinhong Zhou, Chuang Gan, and Anoop Cherian.
3. Memory-Distilled Selection for Noise-Robust Anomaly Detection by Sirojbek Safarov, Jaewoo Park, Yoon G. Jung, Kuan-Chuan Peng, Wonchul Kim, Seongdeok Bang, and Octavia Camps.
4. Partial Ring Scan: Revisiting Scan Order in Vision State Space Models by Yi-Kuan Hsieh, Kuan-Chuan Peng, Xin Li, Ming-Ching Chang, Yu-Chee Tseng, and Jun-Wei Hsieh.
Workshop Papers with MERL Authors:
1. WISE: Weighted Iterative Society-of-Experts for Multimodal Multi-Agent Debate with Probabilistic Consensus by Anoop Cherian, Suhas Lohit, and Kuan-Chuan Peng. (Workshop on Scalable Learning and Optimization for Efficient Multimodal AI Agents (SCALE))
2. MIRROR: Multisensory Implicit Rejection-sampled RObotic policy by Amisha Bhaskar, Pratap Tokekar, Stefano Di Cairano, and Alexander Schperberg. (Workshop on Structured Probabilistic Inference & Generative Modeling)
3. Reinforced Neural Processes: Memory-Efficient Time-Series Forecasting with a World-Feedback-Trained Memory Policy by Nibraas Khan, Gordon Wichern, and Christopher R. Laughman. (Workshop on Reinforcement Learning from World Feedback (RLxF))
4. Connecting Low-Rank Adapters and Policy Stability in GRPO Fine-Tuning by Antonin Rottman, Francesco Tonin, Yongtao Wu, Toshiaki Koike-Akino, and Volkan Cevher. (Workshop on Connecting Low-rank Representations in AI (CoLorAI))
5. EinSort: Sorting is All We Need for Tensorizing LLM by Toshiaki Koike-Akino, Jing Liu, and Ye Wang. (Workshop on Connecting Low-rank Representations in AI (CoLorAI))
6. Temper and Tilt Lead to SLOP: Reward Hacking Mitigation with Inference-Time Alignment by Ye Wang, and Jing Liu, and Toshiaki Koike-Akino. (Workshop on Agents in the Wild: Safety, Security, and Beyond)
- MERL researchers are proud to present 4 main conference papers and 6 workshop papers at ICML 2026. ICML, taking place from July 6-11 in Seoul, South Korea, is a premier international conference in machine learning.
-
EVENT MERL Contributes to ICASSP 2026 Date: Monday, May 4, 2026 - , May 8, 2026
Location: Barcelona, Spain
MERL Contacts: Wael H. Ali; Petros T. Boufounos; Chiori Hori; Jonathan Le Roux; Yanting Ma; Hassan Mansour; Yoshiki Masuyama; Joshua Rapp; Anthony Vetro; Pu (Perry) Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Computational Sensing, Computer Vision, Machine Learning, Optimization, Signal Processing, Speech & AudioBrief- MERL has made numerous contributions to both the organization and technical program of ICASSP 2026, which is being held in Barcelona, Spain from May 4-8, 2026.
Sponsorship
MERL is proud to be a Silver Patron of the conference and will participate in the student job fair on Thursday, May 7. Please join this session to learn more about employment opportunities at MERL, including openings for research scientists, post-docs, and interns. MERL Distinguished Research Scientists Petros T. Boufounos and Jonathan Le Roux will also present a spotlight session on MERL’s research in signal processing on Tuesday, May 5 at 13:05. Finally, MERL will sponsor a photo booth on Thursday, May 7 and Friday, May 8, where ICASSP participants can take professional photos with friends and colleagues, which will be emailed to them.
MERL is also pleased to be the sponsor of two IEEE Awards that will be presented at the conference. We congratulate Prof. Nasir Ahmed, the recipient of the 2026 IEEE Fourier Award for Signal Processing, and Dr. Alex Acero, the recipient of the 2026 IEEE James L. Flanagan Speech and Audio Processing Award.
Technical Program
MERL is presenting 8 papers in the main conference on a wide range of topics including source separation, spatial audio, neural audio codecs, radar-based pose estimation, camera-based airflow sensing, radar array processing, and optimization. Another paper on neural speech codecs will be presented at the Low-Resource Audio Codec (LRAC) Satellite Workshop. MERL researchers will also present two articles published in IEEE Open Journal of Signal Processing (OJSP) on music source separation and head-related transfer function (HRTF) modeling. Finally, Speech and Audio Team members Yoshiki Masuyama and Jonathan Le Roux co-organized a Special Session on Neural Spatial Audio Processing, which will feature six oral presentations.
About ICASSP
ICASSP is the flagship conference of the IEEE Signal Processing Society, and the world's largest and most comprehensive technical conference focused on the research advances and latest technological development in signal and information processing. The event attracts more than 4000 participants each year.
- MERL has made numerous contributions to both the organization and technical program of ICASSP 2026, which is being held in Barcelona, Spain from May 4-8, 2026.
See All News & Events for Gordon -
-
Awards
-
AWARD MERL Team Wins DCASE 2026 Challenge on Anomalous Sound Detection for Machine Condition Monitoring Date: June 30, 2026
Awarded to: Takuya Fujimura, Gordon Wichern, Yoshiki Masuyama, Christoph Boeddeker, Kohei Saijo, Julius Richter, Takahiro Edo, and Jonathan Le Roux
MERL Contacts: Christoph Boeddeker; Takahiro Edo; Jonathan Le Roux; Yoshiki Masuyama; Julius Richter; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Signal Processing, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 51 teams in the DCASE 2026 Challenge’s Task 2, “Noise-aware Unsupervised Anomalous Sound Detection for Machine Condition Monitoring.” The team was led by MERL intern Takuya Fujimura, and also included Gordon Wichern, Yoshiki Masuyama, Christoph Boeddeker, Kohei Saijo, Julius Richter, Takahiro Edo, and Jonathan Le Roux.
The IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), started in 2013, has been organized yearly since 2016, and gathers challenges on multiple tasks related to the detection, analysis, and generation of sound events. This year, the DCASE 2026 Challenge received 421 submissions from 135 teams across seven tasks.
The MERL team won Task 2, Noise-aware Unsupervised Anomalous Sound Detection for Machine Condition Monitoring, which aims at building noise-robust systems for automatically detecting machine failure via microphones when only normal machine operating data is available for system development. Task 2 was by far the most popular out of the 7 DCASE 2026 tasks, with 51 teams submitting 168 entries. The MERL team's system was built around MERL’s recently proposed paradigm of noise-aware self-supervised learning, which extracts noise robust features leveraging two-channel recordings, in which one microphone is used to capture noise. Anomaly detection is then performed in the extracted denoised feature space using advanced score normalization. The team's best submission obtained a composite score of 70.24% on five evaluation machines, largely outperforming the 2nd best team's 65.45%.
MERL also participated in Task 4, Spatial Semantic Segmentation of Sound Scenes (S5) and placed 3rd out of 10 teams in separation performance. Our cascaded system consists of universal sound separation with source counting, source classification, and class-aware refinement, where the separation and refinement modules are built upon MERL's TF-Locoformer separation technology. Notably, the team's best submission obtained a label prediction accuracy of 76.92% on the evaluation set, largely outperforming the 2nd best team's 65.54%.
- MERL's Speech & Audio team ranked 1st out of 51 teams in the DCASE 2026 Challenge’s Task 2, “Noise-aware Unsupervised Anomalous Sound Detection for Machine Condition Monitoring.” The team was led by MERL intern Takuya Fujimura, and also included Gordon Wichern, Yoshiki Masuyama, Christoph Boeddeker, Kohei Saijo, Julius Richter, Takahiro Edo, and Jonathan Le Roux.
-
AWARD MERL team wins the Generative Data Augmentation of Room Acoustics (GenDARA) 2025 Challenge Date: April 7, 2025
Awarded to: Christopher Ick, Gordon Wichern, Yoshiki Masuyama, François G. Germain, and Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Yoshiki Masuyama; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 3 teams in the Generative Data Augmentation of Room Acoustics (GenDARA) 2025 Challenge, which focused on “generating room impulse responses (RIRs) to supplement a small set of measured examples and using the augmented data to train speaker distance estimation (SDE) models". The team was led by MERL intern Christopher Ick, and also included Gordon Wichern, Yoshiki Masuyama, François G. Germain, and Jonathan Le Roux.
The GenDARA Challenge was organized as part of the Generative Data Augmentation (GenDA) workshop at the 2025 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2025), and held on April 7, 2025 in Hyderabad, India. Yoshiki Masuyama presented the team's method, "Data Augmentation Using Neural Acoustic Fields With Retrieval-Augmented Pre-training".
The GenDARA challenge aims to promote the use of generative AI to synthesize RIRs from limited room data, as collecting or simulating RIR datasets at scale remains a significant challenge due to high costs and trade-offs between accuracy and computational efficiency. The challenge asked participants to first develop RIR generation systems capable of expanding a sparse set of labeled room impulse responses by generating RIRs at new source–receiver positions. They were then tasked with using this augmented dataset to train speaker distance estimation systems. Ranking was determined by the overall performance on the downstream SDE task. MERL’s approach to the GenDARA challenge centered on a geometry-aware neural acoustic field model that was first pre-trained on a large external RIR dataset to learn generalizable mappings from 3D room geometry to room impulse responses. For each challenge room, the model was then adapted or fine-tuned using the small number of provided RIRs, enabling high-fidelity generation of RIRs at unseen source–receiver locations. These augmented RIR sets were subsequently used to train the SDE system, improving speaker distance estimation by providing richer and more diverse acoustic training data.
- MERL's Speech & Audio team ranked 1st out of 3 teams in the Generative Data Augmentation of Room Acoustics (GenDARA) 2025 Challenge, which focused on “generating room impulse responses (RIRs) to supplement a small set of measured examples and using the augmented data to train speaker distance estimation (SDE) models". The team was led by MERL intern Christopher Ick, and also included Gordon Wichern, Yoshiki Masuyama, François G. Germain, and Jonathan Le Roux.
-
AWARD MERL team wins the Listener Acoustic Personalisation (LAP) 2024 Challenge Date: August 29, 2024
Awarded to: Yoshiki Masuyama, Gordon Wichern, Francois G. Germain, Christopher Ick, and Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Gordon Wichern; Yoshiki Masuyama
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 7 teams in Task 2 of the 1st SONICOM Listener Acoustic Personalisation (LAP) Challenge, which focused on "Spatial upsampling for obtaining a high-spatial-resolution HRTF from a very low number of directions". The team was led by Yoshiki Masuyama, and also included Gordon Wichern, Francois Germain, MERL intern Christopher Ick, and Jonathan Le Roux.
The LAP Challenge workshop and award ceremony was hosted by the 32nd European Signal Processing Conference (EUSIPCO 24) on August 29, 2024 in Lyon, France. Yoshiki Masuyama presented the team's method, "Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization", and received the award from Prof. Michele Geronazzo (University of Padova, IT, and Imperial College London, UK), Chair of the Challenge's Organizing Committee.
The LAP challenge aims to explore challenges in the field of personalized spatial audio, with the first edition focusing on the spatial upsampling and interpolation of head-related transfer functions (HRTFs). HRTFs with dense spatial grids are required for immersive audio experiences, but their recording is time-consuming. Although HRTF spatial upsampling has recently shown remarkable progress with approaches involving neural fields, HRTF estimation accuracy remains limited when upsampling from only a few measured directions, e.g., 3 or 5 measurements. The MERL team tackled this problem by proposing a retrieval-augmented neural field (RANF). RANF retrieves a subject whose HRTFs are close to those of the target subject at the measured directions from a library of subjects. The HRTF of the retrieved subject at the target direction is fed into the neural field in addition to the desired sound source direction. The team also developed a neural network architecture that can handle an arbitrary number of retrieved subjects, inspired by a multi-channel processing technique called transform-average-concatenate.
- MERL's Speech & Audio team ranked 1st out of 7 teams in Task 2 of the 1st SONICOM Listener Acoustic Personalisation (LAP) Challenge, which focused on "Spatial upsampling for obtaining a high-spatial-resolution HRTF from a very low number of directions". The team was led by Yoshiki Masuyama, and also included Gordon Wichern, Francois Germain, MERL intern Christopher Ick, and Jonathan Le Roux.
-
AWARD MERL team wins the Audio-Visual Speech Enhancement (AVSE) 2023 Challenge Date: December 16, 2023
Awarded to: Zexu Pan, Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux
MERL Contacts: Chiori Hori; Jonathan Le Roux; Gordon Wichern; Yoshiki Masuyama
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
The AVSE challenge aims to design better speech enhancement systems by harnessing the visual aspects of speech (such as lip movements and gestures) in a manner similar to the brain’s multi-modal integration strategies. MERL’s system was a scenario-aware audio-visual TF-GridNet, that incorporates the face recording of a target speaker as a conditioning factor and also recognizes whether the predominant interference signal is speech or background noise. In addition to outperforming all competing systems in terms of objective metrics by a wide margin, in a listening test, MERL’s model achieved the best overall word intelligibility score of 84.54%, compared to 57.56% for the baseline and 80.41% for the next best team. The Fisher’s least significant difference (LSD) was 2.14%, indicating that our model offered statistically significant speech intelligibility improvements compared to all other systems.
- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
-
AWARD MERL Intern and Researchers Win ICASSP 2023 Best Student Paper Award Date: June 9, 2023
Awarded to: Darius Petermann, Gordon Wichern, Aswin Subramanian, Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Gordon Wichern
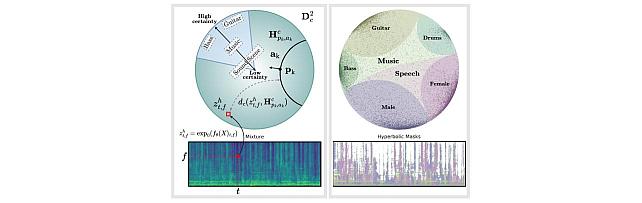
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- Former MERL intern Darius Petermann (Ph.D. Candidate at Indiana University) has received a Best Student Paper Award at the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023) for the paper "Hyperbolic Audio Source Separation", co-authored with MERL researchers Gordon Wichern and Jonathan Le Roux, and former MERL researcher Aswin Subramanian. The paper presents work performed during Darius's internship at MERL in the summer 2022. The paper introduces a framework for audio source separation using embeddings on a hyperbolic manifold that compactly represent the hierarchical relationship between sound sources and time-frequency features. Additionally, the code associated with the paper is publicly available at https://github.com/merlresearch/hyper-unmix.
ICASSP is the flagship conference of the IEEE Signal Processing Society (SPS). ICASSP 2023 was held in the Greek island of Rhodes from June 04 to June 10, 2023, and it was the largest ICASSP in history, with more than 4000 participants, over 6128 submitted papers and 2709 accepted papers. Darius’s paper was first recognized as one of the Top 3% of all papers accepted at the conference, before receiving one of only 5 Best Student Paper Awards during the closing ceremony.
- Former MERL intern Darius Petermann (Ph.D. Candidate at Indiana University) has received a Best Student Paper Award at the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023) for the paper "Hyperbolic Audio Source Separation", co-authored with MERL researchers Gordon Wichern and Jonathan Le Roux, and former MERL researcher Aswin Subramanian. The paper presents work performed during Darius's internship at MERL in the summer 2022. The paper introduces a framework for audio source separation using embeddings on a hyperbolic manifold that compactly represent the hierarchical relationship between sound sources and time-frequency features. Additionally, the code associated with the paper is publicly available at https://github.com/merlresearch/hyper-unmix.
-
AWARD Joint CMU-MERL team wins DCASE2023 Challenge on Automated Audio Captioning Date: June 1, 2023
Awarded to: Shih-Lun Wu, Xuankai Chang, Gordon Wichern, Jee-weon Jung, Francois Germain, Jonathan Le Roux, Shinji Watanabe
MERL Contacts: Jonathan Le Roux; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- A joint team consisting of members of CMU Professor and MERL Alumn Shinji Watanabe's WavLab and members of MERL's Speech & Audio team ranked 1st out of 11 teams in the DCASE2023 Challenge's Task 6A "Automated Audio Captioning". The team was led by student Shih-Lun Wu and also featured Ph.D. candidate Xuankai Chang, Postdoctoral research associate Jee-weon Jung, Prof. Shinji Watanabe, and MERL researchers Gordon Wichern, Francois Germain, and Jonathan Le Roux.
The IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), started in 2013, has been organized yearly since 2016, and gathers challenges on multiple tasks related to the detection, analysis, and generation of sound events. This year, the DCASE2023 Challenge received over 428 submissions from 123 teams across seven tasks.
The CMU-MERL team competed in the Task 6A track, Automated Audio Captioning, which aims at generating informative descriptions for various sounds from nature and/or human activities. The team's system made strong use of large pretrained models, namely a BEATs transformer as part of the audio encoder stack, an Instructor Transformer encoding ground-truth captions to derive an audio-text contrastive loss on the audio encoder, and ChatGPT to produce caption mix-ups (i.e., grammatical and compact combinations of two captions) which, together with the corresponding audio mixtures, increase not only the amount but also the complexity and diversity of the training data. The team's best submission obtained a SPIDEr-FL score of 0.327 on the hidden test set, largely outperforming the 2nd best team's 0.315.
- A joint team consisting of members of CMU Professor and MERL Alumn Shinji Watanabe's WavLab and members of MERL's Speech & Audio team ranked 1st out of 11 teams in the DCASE2023 Challenge's Task 6A "Automated Audio Captioning". The team was led by student Shih-Lun Wu and also featured Ph.D. candidate Xuankai Chang, Postdoctoral research associate Jee-weon Jung, Prof. Shinji Watanabe, and MERL researchers Gordon Wichern, Francois Germain, and Jonathan Le Roux.
-
AWARD Best Poster Award and Best Video Award at the International Society for Music Information Retrieval Conference (ISMIR) 2020 Date: October 15, 2020
Awarded to: Ethan Manilow, Gordon Wichern, Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Gordon Wichern
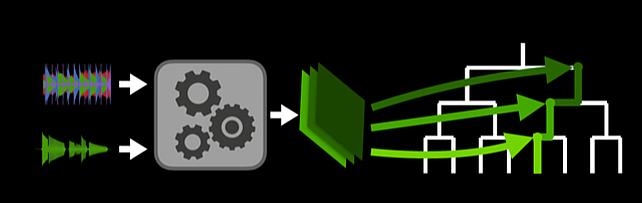
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- Former MERL intern Ethan Manilow and MERL researchers Gordon Wichern and Jonathan Le Roux won Best Poster Award and Best Video Award at the 2020 International Society for Music Information Retrieval Conference (ISMIR 2020) for the paper "Hierarchical Musical Source Separation". The conference was held October 11-14 in a virtual format. The Best Poster Awards and Best Video Awards were awarded by popular vote among the conference attendees.
The paper proposes a new method for isolating individual sounds in an audio mixture that accounts for the hierarchical relationship between sound sources. Many sounds we are interested in analyzing are hierarchical in nature, e.g., during a music performance, a hi-hat note is one of many such hi-hat notes, which is one of several parts of a drumkit, itself one of many instruments in a band, which might be playing in a bar with other sounds occurring. Inspired by this, the paper re-frames the audio source separation problem as hierarchical, combining similar sounds together at certain levels while separating them at other levels, and shows on a musical instrument separation task that a hierarchical approach outperforms non-hierarchical models while also requiring less training data. The paper, poster, and video can be seen on the paper page on the ISMIR website.
- Former MERL intern Ethan Manilow and MERL researchers Gordon Wichern and Jonathan Le Roux won Best Poster Award and Best Video Award at the 2020 International Society for Music Information Retrieval Conference (ISMIR 2020) for the paper "Hierarchical Musical Source Separation". The conference was held October 11-14 in a virtual format. The Best Poster Awards and Best Video Awards were awarded by popular vote among the conference attendees.
-
-
Research Highlights
-
Internships with Gordon
See All Internships at MERL -
MERL Publications
- , "NABEATs: Noise-Aware Audio Representation Learning", arXiv, July 2026.BibTeX arXiv
- @article{Fujimura2026jul,
- author = {Fujimura, Takuya and Masuyama, Yoshiki and Wichern, Gordon and Boeddeker, Christoph and Richter, Julius and {Le Roux}, Jonathan},
- title = {{NABEATs: Noise-Aware Audio Representation Learning}},
- journal = {arXiv},
- year = 2026,
- month = jul,
- url = {https://arxiv.org/abs/2607.16688}
- }
- , "Technical Report for MERL’s Real-TSE Challenge Submission," Tech. Rep. TR2026-112, Mitsubishi Electric Research Laboratories, July 2026.BibTeX TR2026-112 PDF
- @techreport{Klement2026jul2,
- author = {Klement, Dominik and Masuyama, Yoshiki and Boeddeker, Christoph and Saijo, Kohei and Richter, Julius and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{Technical Report for MERL’s Real-TSE Challenge Submission}},
- institution = {Real-TSE Challenge},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-112}
- }
- , "Reinforced Neural Processes: Memory-Efficient Time-Series Forecasting with a World-Feedback-Trained Memory Policy", ICML Workshop on Reinforcement Learning from World Feedback (RLxF), July 2026.BibTeX TR2026-095 PDF
- @inproceedings{Khan2026jul,
- author = {Khan, Nibraas and Wichern, Gordon and Laughman, Christopher R.},
- title = {{Reinforced Neural Processes: Memory-Efficient Time-Series Forecasting with a World-Feedback-Trained Memory Policy}},
- booktitle = {ICML Workshop on Reinforcement Learning from World Feedback (RLxF)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-095}
- }
- , "The MERL Systems for DCASE 2026 Challenge Task 2," Tech. Rep. TR2026-100, IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), June 2026.BibTeX TR2026-100 PDF
- @techreport{Fujimura2026jun,
- author = {{Fujimura, Takuya and Wichern, Gordon and Masuyama, Yoshiki and Boeddeker, Christoph and Saijo, Kohei and Richter, Julius and Edo, Takahiro and Le Roux, Jonathan}},
- title = {{The MERL Systems for DCASE 2026 Challenge Task 2}},
- institution = {IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-100}
- }
- , "The MERL Systems for DCASE 2026 Challenge Task 4," Tech. Rep. TR2026-098, IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), June 2026.BibTeX TR2026-098 PDF
- @techreport{Saijo2026jun,
- author = {{Saijo, Kohei and Masuyama, Yoshiki and Boeddeker, Christoph and Wichern, Gordon and Richter, Julius and Edo, Takahiro and Le Roux, Jonathan}},
- title = {{The MERL Systems for DCASE 2026 Challenge Task 4}},
- institution = {IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-098}
- }
- , "NABEATs: Noise-Aware Audio Representation Learning", arXiv, July 2026.
-
Other Publications
- , "Low-Latency approximation of bidirectional recurrent networks for speech denoising", 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), Oct 2017, pp. 66-70.BibTeX
- @Inproceedings{8169996,
- author = {Wichern, G. and Lukin, A.},
- title = {Low-Latency approximation of bidirectional recurrent networks for speech denoising},
- booktitle = {2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
- year = 2017,
- pages = {66--70},
- month = {Oct}
- }
- , "Quantitative Analysis of Masking in Multitrack Mixes Using Loudness Loss", Sep 2016, Audio Engineering Society Convention 141.BibTeX External
- @Conference{wichern2016quantitative,
- author = {Wichern, G. and Robertson, H. and Wishnick, A.},
- title = {Quantitative Analysis of Masking in Multitrack Mixes Using Loudness Loss},
- booktitle = {Audio Engineering Society Convention 141},
- year = 2016,
- month = {Sep},
- url = {http://www.aes.org/e-lib/browse.cfm?elib=18450}
- }
- , "Comparison of Loudness Features for Automatic Level Adjustment in Mixing", Oct 2015, Audio Engineering Society Convention 139.BibTeX External
- @Conference{wichern2015comparison,
- author = {Wichern, G. and Wishnick, A. and Lukin, A. and Robertson, H.},
- title = {Comparison of Loudness Features for Automatic Level Adjustment in Mixing},
- booktitle = {Audio Engineering Society Convention 139},
- year = 2015,
- month = {Oct},
- url = {http://www.aes.org/e-lib/browse.cfm?elib=17928}
- }
- , "Noise adaptive optimization of matrix initialization for frequency-domain independent component analysis", Digital Signal Processing, Vol. 23, No. 1, pp. 1-8, 2013.BibTeX
- @Article{yamada2013noise,
- author = {Yamada, M. and Wichern, G. and Kondo, K. and Sugiyama, M. and Sawada, H.},
- title = {Noise adaptive optimization of matrix initialization for frequency-domain independent component analysis},
- journal = {Digital Signal Processing},
- year = 2013,
- volume = 23,
- number = 1,
- pages = {1--8},
- publisher = {Academic Press}
- }
- , "Improving the accuracy of least-squares probabilistic classifiers", IEICE transactions on information and systems, Vol. 94, No. 6, pp. 1337-1340, 2011.BibTeX
- @Article{yamada2011improving,
- author = {Yamada, M. and Sugiyama, M. and Wichern, G. and Simm, J.},
- title = {Improving the accuracy of least-squares probabilistic classifiers},
- journal = {IEICE transactions on information and systems},
- year = 2011,
- volume = 94,
- number = 6,
- pages = {1337--1340},
- publisher = {The Institute of Electronics, Information and Communication Engineers}
- }
- , "Audio content-based feature extraction algorithms using J-DSP for arts, media and engineering courses", 2010 IEEE Frontiers in Education Conference (FIE), Oct 2010, pp. T1F-1-T1F-6.BibTeX
- @Inproceedings{5673157,
- author = {Shah, M. and Wichern, G. and Spanias, A. and Thornburg, H.},
- title = {Audio content-based feature extraction algorithms using J-DSP for arts, media and engineering courses},
- booktitle = {2010 IEEE Frontiers in Education Conference (FIE)},
- year = 2010,
- pages = {T1F--1--T1F--6},
- month = {Oct}
- }
- , "Segmentation, Indexing, and Retrieval for Environmental and Natural Sounds", IEEE Transactions on Audio, Speech, and Language Processing, Vol. 18, No. 3, pp. 688-707, March 2010.BibTeX
- @Article{5410056,
- author = {Wichern, G. and Xue, J. and Thornburg, H. and Mechtley, B. and Spanias, A.},
- title = {Segmentation, Indexing, and Retrieval for Environmental and Natural Sounds},
- journal = {IEEE Transactions on Audio, Speech, and Language Processing},
- year = 2010,
- volume = 18,
- number = 3,
- pages = {688--707},
- month = mar
- }
- , "Direct importance estimation with probabilistic principal component analyzers", 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, March 2010, pp. 1962-1965.BibTeX
- @Inproceedings{5495290,
- author = {Yamada, M. and Sugiyama, M. and Wichern, G.},
- title = {Direct importance estimation with probabilistic principal component analyzers},
- booktitle = {2010 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2010,
- pages = {1962--1965},
- month = mar
- }
- , "Acceleration of sequence kernel computation for real-time speaker identification", 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, March 2010, pp. 1626-1629.BibTeX
- @Inproceedings{5495542,
- author = {Yamada, M. and Sugiyama, M. and Wichern, G. and Matsui, T.},
- title = {Acceleration of sequence kernel computation for real-time speaker identification},
- booktitle = {2010 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2010,
- pages = {1626--1629},
- month = mar
- }
- , "Automatic audio tagging using covariate shift adaptation", 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, March 2010, pp. 253-256.BibTeX
- @Inproceedings{5495973,
- author = {Wichern, G. and Yamada, M. and Thornburg, H. and Sugiyama, M. and Spanias, A.},
- title = {Automatic audio tagging using covariate shift adaptation},
- booktitle = {2010 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2010,
- pages = {253--256},
- month = mar
- }
- , "Combining semantic, social, and acoustic similarity for retrieval of environmental sounds", 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, March 2010, pp. 2402-2405.BibTeX
- @Inproceedings{5496225,
- author = {Mechtley, B. and Wichern, G. and Thornburg, H. and Spanias, A.},
- title = {Combining semantic, social, and acoustic similarity for retrieval of environmental sounds},
- booktitle = {2010 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2010,
- pages = {2402--2405},
- month = mar
- }
- , "Re-Sonification of Geographic Sound Activity using Acoustic, Semantic and Social Information", Proceedings of the 16th International Conference on Auditory Display (ICAD2010), 2010.BibTeX
- @Inproceedings{fink2010re,
- author = {Fink, A. and Mechtley, B. and Wichern, G. and Liu, J. and Thornburg, H. and Spanias, A. and Coleman, G.},
- title = {Re-Sonification of Geographic Sound Activity using Acoustic, Semantic and Social Information},
- booktitle = {Proceedings of the 16th International Conference on Auditory Display (ICAD2010)},
- year = 2010,
- organization = {Georgia Institute of Technology}
- }
- , "An ontological framework for retrieving environmental sounds using semantics and acoustic content", EURASIP Journal on Audio, Speech, and Music Processing, Vol. 2010, No. 1, pp. 192363, 2010.BibTeX
- @Article{wichern2010ontological,
- author = {Wichern, G. and Mechtley, B. and Fink, A. and Thornburg, H. and Spanias, A.},
- title = {An ontological framework for retrieving environmental sounds using semantics and acoustic content},
- journal = {EURASIP Journal on Audio, Speech, and Music Processing},
- year = 2010,
- volume = 2010,
- number = 1,
- pages = 192363,
- publisher = {Springer International Publishing}
- }
- , "Direct importance estimation with a mixture of probabilistic principal component analyzers", IEICE Transactions on Information and Systems, Vol. 93, No. 10, pp. 2846-2849, 2010.BibTeX
- @Article{yamada2010direct,
- author = {Yamada, M. and Sugiyama, M. and Wichern, G. and Simm, J.},
- title = {Direct importance estimation with a mixture of probabilistic principal component analyzers},
- journal = {IEICE Transactions on Information and Systems},
- year = 2010,
- volume = 93,
- number = 10,
- pages = {2846--2849},
- publisher = {The Institute of Electronics, Information and Communication Engineers}
- }
- , "Unifying semantic and content-based approaches for retrieval of environmental sounds", 2009 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, Oct 2009, pp. 13-16.BibTeX
- @Inproceedings{5346493,
- author = {Wichern, G. and Thornburg, H. and Spanias, A.},
- title = {Unifying semantic and content-based approaches for retrieval of environmental sounds},
- booktitle = {2009 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics},
- year = 2009,
- pages = {13--16},
- month = {Oct}
- }
- , "Continuous observation and archival of acoustic scenes using wireless sensor networks", 2009 16th International Conference on Digital Signal Processing, July 2009, pp. 1-6.BibTeX
- @Inproceedings{5201082,
- author = {Wichern, G. and Kwon, H. and Spanias, A. and Fink, A. and Thornburg, H.},
- title = {Continuous observation and archival of acoustic scenes using wireless sensor networks},
- booktitle = {2009 16th International Conference on Digital Signal Processing},
- year = 2009,
- pages = {1--6},
- month = jul
- }
- , "Multi-channel audio segmentation for continuous observation and archival of large spaces", 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, April 2009, pp. 237-240.BibTeX
- @Inproceedings{4959564,
- author = {Wichern, G. and Thornburg, H. and Spanias, A.},
- title = {Multi-channel audio segmentation for continuous observation and archival of large spaces},
- booktitle = {2009 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2009,
- pages = {237--240},
- month = apr
- }
- , "Fast query by example of environmental sounds via robust and efficient cluster-based indexing", 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, March 2008, pp. 5-8.BibTeX
- @Inproceedings{4517532,
- author = {Xue, J. and Wichern, G. and Thornburg, H. and Spanias, A.},
- title = {Fast query by example of environmental sounds via robust and efficient cluster-based indexing},
- booktitle = {2008 IEEE International Conference on Acoustics, Speech and Signal Processing},
- year = 2008,
- pages = {5--8},
- month = mar
- }
- , "Distortion-Aware Query-by-Example for Environmental Sounds", 2007 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, Oct 2007, pp. 335-338.BibTeX
- @Inproceedings{4393051,
- author = {Wichern, G. and Xue, J. and Thornburg, H. and Spanias, A.},
- title = {Distortion-Aware Query-by-Example for Environmental Sounds},
- booktitle = {2007 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics},
- year = 2007,
- pages = {335--338},
- month = {Oct}
- }
- , "An Operationally Adaptive System for Rapid Acoustic Transmission Loss Prediction", 2007 International Joint Conference on Neural Networks, Aug 2007, pp. 2262-2267.BibTeX
- @Inproceedings{4371310,
- author = {McCarron, M. and Azimi-Sadjadi, M. R. and Wichem, G. and Mungiole, M.},
- title = {An Operationally Adaptive System for Rapid Acoustic Transmission Loss Prediction},
- booktitle = {2007 International Joint Conference on Neural Networks},
- year = 2007,
- pages = {2262--2267},
- month = {Aug}
- }
- , "Robust Multi-Features Segmentation and Indexing for Natural Sound Environments", 2007 International Workshop on Content-Based Multimedia Indexing, June 2007, pp. 69-76.BibTeX
- @Inproceedings{4275057,
- author = {Wichern, G. and Thornburg, H. and Mechtley, B. and Fink, A. and Tu, K. and Spanias, A.},
- title = {Robust Multi-Features Segmentation and Indexing for Natural Sound Environments},
- booktitle = {2007 International Workshop on Content-Based Multimedia Indexing},
- year = 2007,
- pages = {69--76},
- month = jun
- }
- , "Environmentally adaptive acoustic transmission loss prediction in turbulent and nonturbulent atmospheres", Neural Networks, Vol. 20, No. 4, pp. 484 - 497, 2007.BibTeX External
- @Article{WICHERN2007484,
- author = {Wichern, G. and Azimi-Sadjadi, M. R. and Mungiole, M.},
- title = {Environmentally adaptive acoustic transmission loss prediction in turbulent and nonturbulent atmospheres},
- journal = {Neural Networks},
- year = 2007,
- volume = 20,
- number = 4,
- pages = {484 -- 497},
- note = {Computational Intelligence in Earth and Environmental Sciences},
- url = {http://www.sciencedirect.com/science/article/pii/S089360800700055X}
- }
- , "An Environmentally Adaptive System for Rapid Acoustic Transmission Loss Prediction", The 2006 IEEE International Joint Conference on Neural Network Proceedings, 2006, pp. 5118-5125.BibTeX
- @Inproceedings{1716812,
- author = {Wichern, G. and Azimi-Sadjadi, M. R. and Mungiole, M.},
- title = {An Environmentally Adaptive System for Rapid Acoustic Transmission Loss Prediction},
- booktitle = {The 2006 IEEE International Joint Conference on Neural Network Proceedings},
- year = 2006,
- pages = {5118--5125}
- }
- , "Properties of randomly distributed sparse arrays", Proc. SPIE, 2006, vol. 6201.BibTeX
- @Inproceedings{azimi2006properties,
- author = {Azimi-Sadjadi, MR and Jiang, Y and Wichern, G},
- title = {Properties of randomly distributed sparse arrays},
- booktitle = {Proc. SPIE},
- year = 2006,
- volume = 6201
- }
- , "Unattended sparse acoustic array configurations and beamforming algorithms", Proc. SPIE, 2005, vol. 5796, pp. 40-51.BibTeX
- @Inproceedings{azimi2005unattended,
- author = {Azimi-Sadjadi, MR and Pezeshki, A and Scharf, LL and Wichern, G},
- title = {Unattended sparse acoustic array configurations and beamforming algorithms},
- booktitle = {Proc. SPIE},
- year = 2005,
- volume = 5796,
- pages = {40--51}
- }
- , "Low-Latency approximation of bidirectional recurrent networks for speech denoising", 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), Oct 2017, pp. 66-70.
-
Software & Data Downloads
-
Embracing Cacophony -
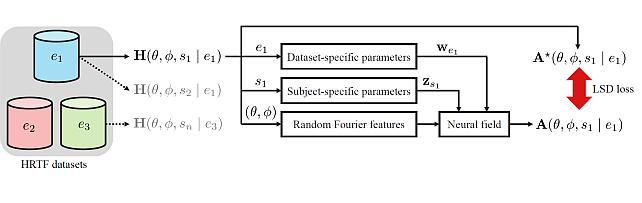
Subject- and Dataset-Aware Neural Field for HRTF Modeling -
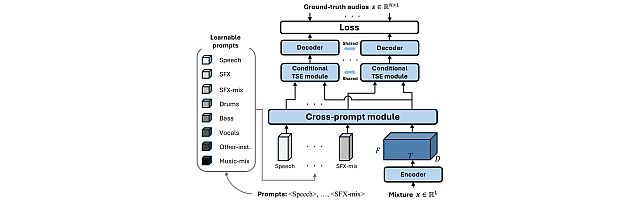
Task-Aware Unified Source Separation -
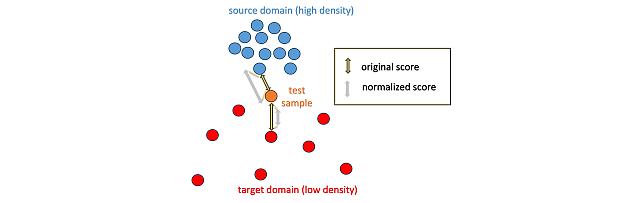
Local Density-Based Anomaly Score Normalization for Domain Generalization -
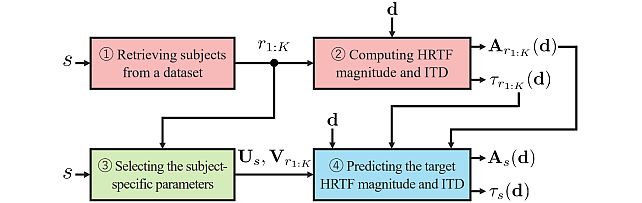
Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization -
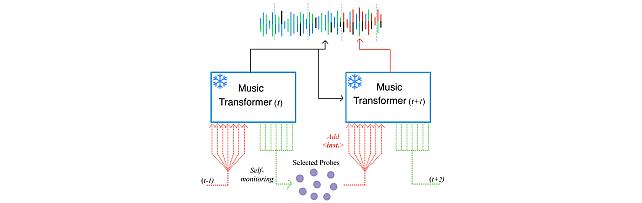
Self-Monitored Inference-Time INtervention for Generative Music Transformers -
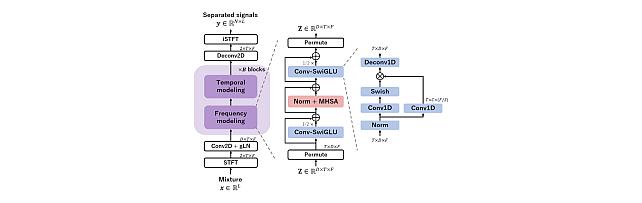
Transformer-based model with LOcal-modeling by COnvolution -
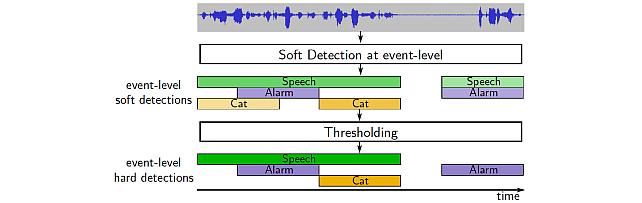
Sound Event Bounding Boxes -
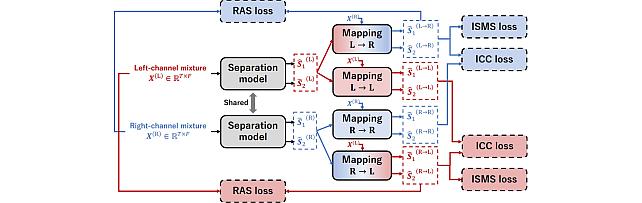
Enhanced Reverberation as Supervision -
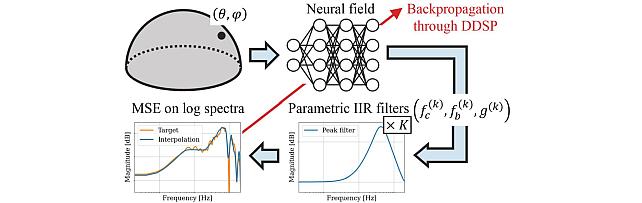
Neural IIR Filter Field for HRTF Upsampling and Personalization -
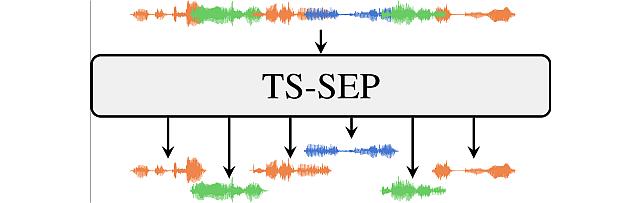
Target-Speaker SEParation -
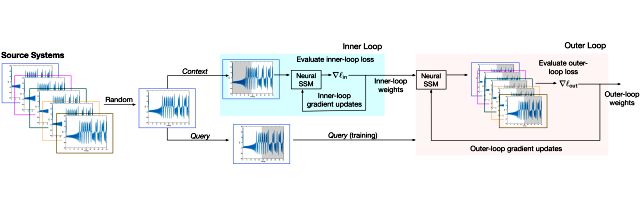
Meta-Learning State Space Models -
Hyperbolic Audio Source Separation -
Hierarchical Musical Instrument Separation
-
-
Videos
-
MERL Issued Patents
-
Title: "Audio Signal Enhancement with Recursive Restoration Employing Deterministic Degradation"
Inventors: Le Roux, Jonathan; Germain, Francois; Wichern, Gordon P; Yen, Hao
Patent No.: 12,609,129
Issue Date: Apr 21, 2026 -
Title: "System and Method for Unsupervised Anomalous Sound Detection"
Inventors: Wichern, Gordon P; Venkatesh, Satvik; Subramanian, Aswin Shanmugam; Le Roux, Jonathan
Patent No.: 12,467,781
Issue Date: Nov 11, 2025 -
Title: "Method and System for Sound Event Localization and Detection"
Inventors: Wichern, Gordon P; Slizovskaia, Olga; Le Roux, Jonathan
Patent No.: 12,452,590
Issue Date: Oct 21, 2025 -
Title: "Method and System for Reverberation Modeling of Speech Signals"
Inventors: Wang, Zhongqiu; Wichern, Gordon P; Le Roux, Jonathan
Patent No.: 12,400,673
Issue Date: Aug 26, 2025 -
Title: "Method and System for Detecting Anomalous Sound"
Inventors: Wichern, Gordon P; Chakrabarty, Ankush; Wang, Zhongqiu; Le Roux, Jonathan
Patent No.: 11,978,476
Issue Date: May 7, 2024 -
Title: "Low-latency speech separation using LC-BLSTM and Teacher-Student Learning"
Inventors: AIHARA, RYO; HANAZAWA, TOSHIYUKI; OKATO, YOHEI; Wichern, Gordon P; Le Roux, Jonathan
Patent No.: 11,798,574
Issue Date: Oct 24, 2023 -
Title: "Method and System for Dereverberation of Speech Signals"
Inventors: Wang, Zhongqiu; Wichern, Gordon P; Le Roux, Jonathan
Patent No.: 11,790,930
Issue Date: Oct 17, 2023 -
Title: "System and Method for Producing Metadata of an Audio Signal"
Inventors: Moritz, Niko; Wichern, Gordon P; Hori, Takaaki; Le Roux, Jonathan
Patent No.: 11,756,551
Issue Date: Sep 12, 2023 -
Title: "Manufacturing Automation using Acoustic Separation Neural Network"
Inventors: Wichern, Gordon P; Le Roux, Jonathan; Pishdadian, Fatemeh
Patent No.: 11,579,598
Issue Date: Feb 14, 2023 -
Title: "System and Method for Hierarchical Audio Source Separation"
Inventors: Wichern, Gordon P; Le Roux, Jonathan; Manilow, Ethan
Patent No.: 11,475,908
Issue Date: Oct 18, 2022 -
Title: "Methods and Systems for Enhancing Audio Signals Corrupted by Noise"
Inventors: Le Roux, Jonathan; Watanabe, Shinji; Hershey, John R.; Wichern, Gordon P
Patent No.: 10,726,856
Issue Date: Jul 28, 2020 -
Title: "Methods and Systems for End-to-End Speech Separation with Unfolded Iterative Phase Reconstruction"
Inventors: Le Roux, Jonathan; Hershey, John R.; Wang, Zhongqiu; Wichern, Gordon P
Patent No.: 10,529,349
Issue Date: Jan 7, 2020
-
Title: "Audio Signal Enhancement with Recursive Restoration Employing Deterministic Degradation"