Artificial Intelligence
Making machines smarter for improved safety, efficiency and comfort.
Our AI research encompasses advances in computer vision, speech and audio processing, as well as data analytics. Key research themes include improved perception based on machine learning techniques, learning control policies through model-based reinforcement learning, as well as cognition and reasoning based on learned semantic representations. We apply our work to a broad range of automotive and robotics applications, as well as building and home systems.
Quick Links
-
Researchers

Jonathan
Le Roux

Toshiaki
Koike-Akino

Ye
Wang

Gordon
Wichern

Anoop
Cherian

Tim K.
Marks

Chiori
Hori

Michael J.
Jones

Jing
Liu

Kieran
Parsons

Suhas
Lohit

Daniel N.
Nikovski

Yoshiki
Masuyama

Kuan-Chuan
Peng

Matthew
Brand

Pu
(Perry)
Wang
Moitreya
Chatterjee

Philip V.
Orlik

Siddarth
Jain

Hassan
Mansour

Petros T.
Boufounos

Radu
Corcodel

Pedro
Miraldo

William S.
Yerazunis

Christoph
Boeddeker

Yebin
Wang

Jianlin
Guo

Arvind
Raghunathan

Hongbo
Sun

Stefano
Di Cairano

Chungwei
Lin

Yanting
Ma

Saviz
Mowlavi

Bingnan
Wang

Takahiro
Edo

Christopher R.
Laughman

Lalit
Manam

Julius
Richter

Alexander
Schperberg

Anthony
Vetro

Jinyun
Zhang

Vedang M.
Deshpande

Kaen
Kogashi

Dehong
Liu

Kei
Suzuki

Abraham P.
Vinod

Kenji
Inomata
-
Awards
-
AWARD MERL Team Wins DCASE 2026 Challenge on Anomalous Sound Detection for Machine Condition Monitoring Date: June 30, 2026
Awarded to: Takuya Fujimura, Gordon Wichern, Yoshiki Masuyama, Christoph Boeddeker, Kohei Saijo, Julius Richter, Takahiro Edo, and Jonathan Le Roux
MERL Contacts: Christoph Boeddeker; Takahiro Edo; Jonathan Le Roux; Yoshiki Masuyama; Julius Richter; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Signal Processing, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 51 teams in the DCASE 2026 Challenge’s Task 2, “Noise-aware Unsupervised Anomalous Sound Detection for Machine Condition Monitoring.” The team was led by MERL intern Takuya Fujimura, and also included Gordon Wichern, Yoshiki Masuyama, Christoph Boeddeker, Kohei Saijo, Julius Richter, Takahiro Edo, and Jonathan Le Roux.
The IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), started in 2013, has been organized yearly since 2016, and gathers challenges on multiple tasks related to the detection, analysis, and generation of sound events. This year, the DCASE 2026 Challenge received 421 submissions from 135 teams across seven tasks.
The MERL team won Task 2, Noise-aware Unsupervised Anomalous Sound Detection for Machine Condition Monitoring, which aims at building noise-robust systems for automatically detecting machine failure via microphones when only normal machine operating data is available for system development. Task 2 was by far the most popular out of the 7 DCASE 2026 tasks, with 51 teams submitting 168 entries. The MERL team's system was built around MERL’s recently proposed paradigm of noise-aware self-supervised learning, which extracts noise robust features leveraging two-channel recordings, in which one microphone is used to capture noise. Anomaly detection is then performed in the extracted denoised feature space using advanced score normalization. The team's best submission obtained a composite score of 70.24% on five evaluation machines, largely outperforming the 2nd best team's 65.45%.
MERL also participated in Task 4, Spatial Semantic Segmentation of Sound Scenes (S5) and placed 3rd out of 10 teams in separation performance. Our cascaded system consists of universal sound separation with source counting, source classification, and class-aware refinement, where the separation and refinement modules are built upon MERL's TF-Locoformer separation technology. Notably, the team's best submission obtained a label prediction accuracy of 76.92% on the evaluation set, largely outperforming the 2nd best team's 65.54%.
- MERL's Speech & Audio team ranked 1st out of 51 teams in the DCASE 2026 Challenge’s Task 2, “Noise-aware Unsupervised Anomalous Sound Detection for Machine Condition Monitoring.” The team was led by MERL intern Takuya Fujimura, and also included Gordon Wichern, Yoshiki Masuyama, Christoph Boeddeker, Kohei Saijo, Julius Richter, Takahiro Edo, and Jonathan Le Roux.
-
AWARD MERL team wins the Generative Data Augmentation of Room Acoustics (GenDARA) 2025 Challenge Date: April 7, 2025
Awarded to: Christopher Ick, Gordon Wichern, Yoshiki Masuyama, François G. Germain, and Jonathan Le Roux
MERL Contacts: Jonathan Le Roux; Yoshiki Masuyama; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 3 teams in the Generative Data Augmentation of Room Acoustics (GenDARA) 2025 Challenge, which focused on “generating room impulse responses (RIRs) to supplement a small set of measured examples and using the augmented data to train speaker distance estimation (SDE) models". The team was led by MERL intern Christopher Ick, and also included Gordon Wichern, Yoshiki Masuyama, François G. Germain, and Jonathan Le Roux.
The GenDARA Challenge was organized as part of the Generative Data Augmentation (GenDA) workshop at the 2025 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2025), and held on April 7, 2025 in Hyderabad, India. Yoshiki Masuyama presented the team's method, "Data Augmentation Using Neural Acoustic Fields With Retrieval-Augmented Pre-training".
The GenDARA challenge aims to promote the use of generative AI to synthesize RIRs from limited room data, as collecting or simulating RIR datasets at scale remains a significant challenge due to high costs and trade-offs between accuracy and computational efficiency. The challenge asked participants to first develop RIR generation systems capable of expanding a sparse set of labeled room impulse responses by generating RIRs at new source–receiver positions. They were then tasked with using this augmented dataset to train speaker distance estimation systems. Ranking was determined by the overall performance on the downstream SDE task. MERL’s approach to the GenDARA challenge centered on a geometry-aware neural acoustic field model that was first pre-trained on a large external RIR dataset to learn generalizable mappings from 3D room geometry to room impulse responses. For each challenge room, the model was then adapted or fine-tuned using the small number of provided RIRs, enabling high-fidelity generation of RIRs at unseen source–receiver locations. These augmented RIR sets were subsequently used to train the SDE system, improving speaker distance estimation by providing richer and more diverse acoustic training data.
- MERL's Speech & Audio team ranked 1st out of 3 teams in the Generative Data Augmentation of Room Acoustics (GenDARA) 2025 Challenge, which focused on “generating room impulse responses (RIRs) to supplement a small set of measured examples and using the augmented data to train speaker distance estimation (SDE) models". The team was led by MERL intern Christopher Ick, and also included Gordon Wichern, Yoshiki Masuyama, François G. Germain, and Jonathan Le Roux.
-
AWARD MERL Wins Awards at NeurIPS LLM Privacy Challenge Date: December 15, 2024
Awarded to: Jing Liu, Ye Wang, Toshiaki Koike-Akino, Tsunato Nakai, Kento Oonishi, Takuya Higashi
MERL Contacts: Toshiaki Koike-Akino; Jing Liu; Ye Wang
Research Areas: Artificial Intelligence, Machine Learning, Information SecurityBrief- The Mitsubishi Electric Privacy Enhancing Technologies (MEL-PETs) team, consisting of a collaboration of MERL and Mitsubishi Electric researchers, won awards at the NeurIPS 2024 Large Language Model (LLM) Privacy Challenge. In the Blue Team track of the challenge, we won the 3rd Place Award, and in the Red Team track, we won the Special Award for Practical Attack.
See All Awards for Artificial Intelligence -
-
News & Events
-
NEWS MERL Presents 4 Main Conference Papers and 6 Workshop Papers at ICML 2026 Date: July 6, 2026 - July 11, 2026
Where: COEX, Seoul, South Korea
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Stefano Di Cairano; Toshiaki Koike-Akino; Christopher R. Laughman; Jing Liu; Suhas Lohit; Kuan-Chuan Peng; Alexander Schperberg; Ye Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Computer Vision, Machine Learning, Signal ProcessingBrief- MERL researchers are proud to present 4 main conference papers and 6 workshop papers at ICML 2026. ICML, taking place from July 6-11 in Seoul, South Korea, is a premier international conference in machine learning.
Main Conference Papers with MERL Authors:
1. Understanding Dynamic Compute Allocation in Recurrent Transformers by Ibraheem Muhammad Moosa, Suhas Lohit, Ye Wang, Moitreya Chatterjee, and Wenpeng Yin.
2. LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior by Qinhong Zhou, Chuang Gan, and Anoop Cherian.
3. Memory-Distilled Selection for Noise-Robust Anomaly Detection by Sirojbek Safarov, Jaewoo Park, Yoon G. Jung, Kuan-Chuan Peng, Wonchul Kim, Seongdeok Bang, and Octavia Camps.
4. Partial Ring Scan: Revisiting Scan Order in Vision State Space Models by Yi-Kuan Hsieh, Kuan-Chuan Peng, Xin Li, Ming-Ching Chang, Yu-Chee Tseng, and Jun-Wei Hsieh.
Workshop Papers with MERL Authors:
1. WISE: Weighted Iterative Society-of-Experts for Multimodal Multi-Agent Debate with Probabilistic Consensus by Anoop Cherian, Suhas Lohit, and Kuan-Chuan Peng. (Workshop on Scalable Learning and Optimization for Efficient Multimodal AI Agents (SCALE))
2. MIRROR: Multisensory Implicit Rejection-sampled RObotic policy by Amisha Bhaskar, Pratap Tokekar, Stefano Di Cairano, and Alexander Schperberg. (Workshop on Structured Probabilistic Inference & Generative Modeling)
3. Reinforced Neural Processes: Memory-Efficient Time-Series Forecasting with a World-Feedback-Trained Memory Policy by Nibraas Khan, Gordon Wichern, and Christopher R. Laughman. (Workshop on Reinforcement Learning from World Feedback (RLxF))
4. Connecting Low-Rank Adapters and Policy Stability in GRPO Fine-Tuning by Antonin Rottman, Francesco Tonin, Yongtao Wu, Toshiaki Koike-Akino, and Volkan Cevher. (Workshop on Connecting Low-rank Representations in AI (CoLorAI))
5. EinSort: Sorting is All We Need for Tensorizing LLM by Toshiaki Koike-Akino, Jing Liu, and Ye Wang. (Workshop on Connecting Low-rank Representations in AI (CoLorAI))
6. Temper and Tilt Lead to SLOP: Reward Hacking Mitigation with Inference-Time Alignment by Ye Wang, and Jing Liu, and Toshiaki Koike-Akino. (Workshop on Agents in the Wild: Safety, Security, and Beyond)
- MERL researchers are proud to present 4 main conference papers and 6 workshop papers at ICML 2026. ICML, taking place from July 6-11 in Seoul, South Korea, is a premier international conference in machine learning.
-
NEWS MERL researchers present 9 papers at IEEE ICRA 2026 Date: June 1, 2026 - June 5, 2026
Where: Vienna, Austria
MERL Contacts: Radu Corcodel; Stefano Di Cairano; Purnanand Elango; Siddarth Jain; Alexander Schperberg; Kento Tomita
Research Areas: Artificial Intelligence, Computer Vision, Control, Dynamical Systems, Machine Learning, Optimization, RoboticsBrief- MERL researchers presented nine papers at the recently concluded IEEE International Conference on Robotics and Automation (ICRA) 2026 in Vienna, Austria. The papers covered a broad set of topics in robotics, including robot perception, visuo-tactile sensing, contact and pose estimation, manipulation, reinforcement learning, diffusion policies, loco-manipulation, contact-implicit trajectory optimization, legged locomotion, localization, and perception-aware planning.
IEEE ICRA is the flagship conference of the IEEE Robotics and Automation Society and the world’s largest and most comprehensive technical conference focused on research advances and the latest technological developments in robotics. The event attracts nearly 8,000 participants and receives more than 5,000 paper submissions.
- MERL researchers presented nine papers at the recently concluded IEEE International Conference on Robotics and Automation (ICRA) 2026 in Vienna, Austria. The papers covered a broad set of topics in robotics, including robot perception, visuo-tactile sensing, contact and pose estimation, manipulation, reinforcement learning, diffusion policies, loco-manipulation, contact-implicit trajectory optimization, legged locomotion, localization, and perception-aware planning.
See All News & Events for Artificial Intelligence -
-
Research Highlights
-
LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior -
Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting -
AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects -
SLAM-MER: Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling -
Parallel Rigidity Matters for Bundle Adjustment -
LLMPhy: Parameter-Identifiable Physical Reasoning Combining Large Language Models and Physics Engines -
PS-NeuS: A Probability-guided Sampler for Neural Implicit Surface Rendering -
Quantum AI Technology -
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models -
Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-Aware Spatio-Temporal Sampling -
Private, Secure, and Reliable Artificial Intelligence -
Steered Diffusion -
Sustainable AI -
Robust Machine Learning -
mmWave Beam-SNR Fingerprinting (mmBSF) -
Video Anomaly Detection -
Biosignal Processing for Human-Machine Interaction -
Task-aware Unified Source Separation - Audio Examples
-
-
Internships
-
SA0302: Internship - Audio Processing for Moving Sounds
-
CV0101: Internship - Multimodal Algorithmic Reasoning
-
SA0191: Internship - Human-Robot Interaction Based on Multimodal Scene Understanding
See All Internships for Artificial Intelligence -
-
Openings
-
SA0297: Postdoctoral Research Fellow - AI for Science
-
CI0177: Postdoctoral Research Fellow - Agentic AI
See All Openings at MERL -
-
Recent Publications
- , "Temper and Tilt Lead to SLOP: Reward Hacking Mitigation with Inference-Time Alignment", International Conference on Machine Learning (ICML) Workshop on Agents in the Wild: Safety, Security, and Beyond, July 2026.BibTeX TR2026-094 PDF Presentation
- @inproceedings{Wang2026jul,
- author = {{Wang, Ye and Liu, Jing and Koike-Akino, Toshiaki}},
- title = {{Temper and Tilt Lead to SLOP: Reward Hacking Mitigation with Inference-Time Alignment}},
- booktitle = {International Conference on Machine Learning (ICML) Workshop on Agents in the Wild: Safety, Security, and Beyond},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-094}
- }
- , "EinSort: Sorting is All We Need for Tensorizing LLM", International Conference on Machine Learning (ICML) Workshop, July 2026.BibTeX TR2026-093 PDF Presentation
- @inproceedings{Koike-Akino2026jul,
- author = {{Koike-Akino, Toshiaki and Liu, Jing and Wang, Ye}},
- title = {{EinSort: Sorting is All We Need for Tensorizing LLM}},
- booktitle = {International Conference on Machine Learning (ICML) Workshop},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-093}
- }
- , "Connecting Low-Rank Adapters and Policy Stability in GRPO Fine-Tuning", International Conference on Machine Learning (ICML) Workshop, July 2026.BibTeX TR2026-092 PDF
- @inproceedings{Rottman2026jul,
- author = {Rottman, Antonin and Tonin, Francesco and Wu, Yongtao and Koike-Akino, Toshiaki and Cevher, Volkan},
- title = {{Connecting Low-Rank Adapters and Policy Stability in GRPO Fine-Tuning}},
- booktitle = {International Conference on Machine Learning (ICML) Workshop},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-092}
- }
- , "MIRROR: Multisensory Implicit Rejection-sampled RObotic policy", ICML 2026 Workshop on Structured Probabilistic Inference & Generative Modeling, July 2026.BibTeX TR2026-096 PDF
- @inproceedings{Bhaskar2026jul,
- author = {Bhaskar, Amisha and Tokekar, Pratap and {Di Cairano}, Stefano and Schperberg, Alexander},
- title = {{MIRROR: Multisensory Implicit Rejection-sampled RObotic policy}},
- booktitle = {ICML 2026 Workshop on Structured Probabilistic Inference \& Generative Modeling},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-096}
- }
- , "Partial Ring Scan: Revisiting Scan Order in Vision State Space Models", International Conference on Machine Learning (ICML), July 2026.BibTeX TR2026-091 PDF
- @inproceedings{Hsieh2026jul,
- author = {Hsieh, Yi-Kuan and Peng, Kuan-Chuan and Li, Xin and Chang, Ming-Ching and Tseng, Yu-Chee and Hsieh, Jun-Wei},
- title = {{Partial Ring Scan: Revisiting Scan Order in Vision State Space Models}},
- booktitle = {International Conference on Machine Learning (ICML)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-091}
- }
- , "Reinforced Neural Processes: Memory-Efficient Time-Series Forecasting with a World-Feedback-Trained Memory Policy", ICML Workshop on Reinforcement Learning from World Feedback (RLxF), July 2026.BibTeX TR2026-095 PDF
- @inproceedings{Khan2026jul,
- author = {Khan, Nibraas and Wichern, Gordon and Laughman, Christopher R.},
- title = {{Reinforced Neural Processes: Memory-Efficient Time-Series Forecasting with a World-Feedback-Trained Memory Policy}},
- booktitle = {ICML Workshop on Reinforcement Learning from World Feedback (RLxF)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-095}
- }
- , "Understanding Dynamic Compute Allocation in Recurrent Transformers", International Conference on Machine Learning (ICML), July 2026.BibTeX TR2026-090 PDF Software Presentation
- @inproceedings{Moosa2026jul,
- author = {{Moosa, Ibraheem Muhammad and Lohit, Suhas and Wang, Ye and Chatterjee, Moitreya and Yin, Wenpeng}},
- title = {{Understanding Dynamic Compute Allocation in Recurrent Transformers}},
- booktitle = {International Conference on Machine Learning (ICML)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-090}
- }
- , "Memory-Distilled Selection for Noise-Robust Anomaly Detection", International Conference on Machine Learning (ICML), July 2026.BibTeX TR2026-089 PDF
- @inproceedings{Safarov2026jul,
- author = {{Safarov, Sirojbek and Park, Jaewoo and Jung, Yoon G. and Peng, Kuan-Chuan and Kim, Wonchul and Bang, Seongdeok and Camps, Octavia}},
- title = {{Memory-Distilled Selection for Noise-Robust Anomaly Detection}},
- booktitle = {International Conference on Machine Learning (ICML)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-089}
- }
- , "Temper and Tilt Lead to SLOP: Reward Hacking Mitigation with Inference-Time Alignment", International Conference on Machine Learning (ICML) Workshop on Agents in the Wild: Safety, Security, and Beyond, July 2026.
-
Videos
-
Software & Data Downloads
-
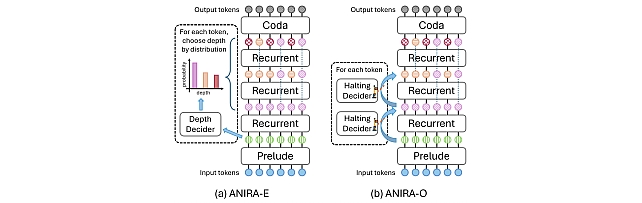
Understanding Dynamic Compute Allocation in Recurrent Transformers -

Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior -
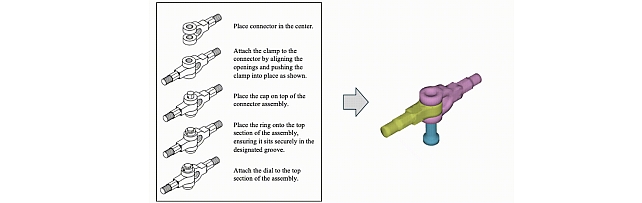
Physics-Aware Assembly of Complex Industrial Objects -
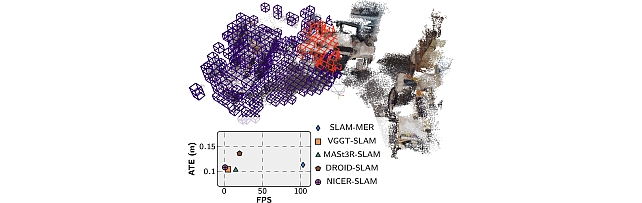
Mitsubishi Electric Research framework for visual SLAM -
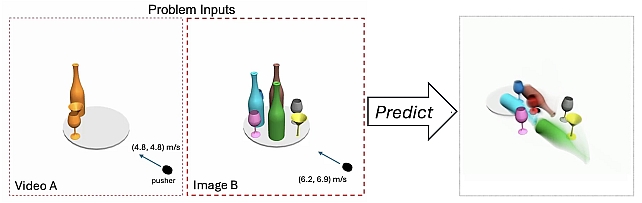
Parameter-Identifiable Physical Reasoning Combining Large Language Models and Physics Engines -
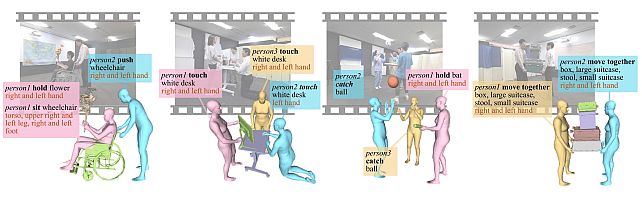
MMHOI Dataset: Modeling Complex 3D Multi-Human Multi-Object Interactions -
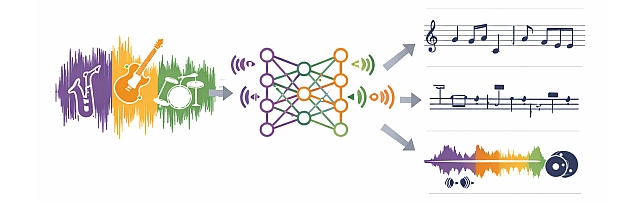
Embracing Cacophony -
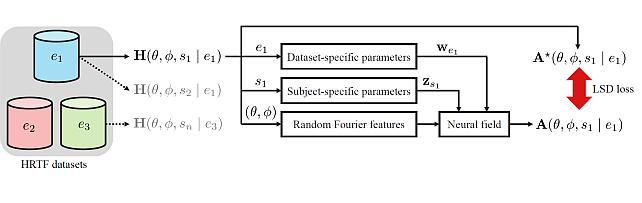
Subject- and Dataset-Aware Neural Field for HRTF Modeling -
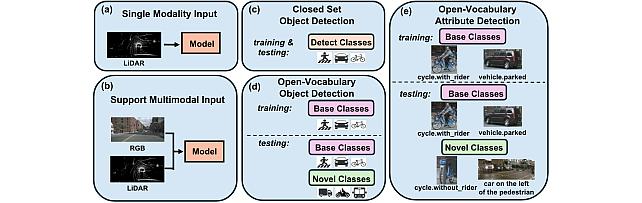
Open Vocabulary Attribute Detection Dataset -
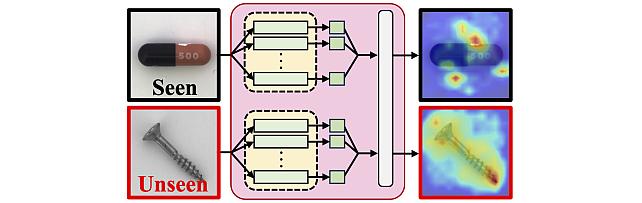
Long-Tailed Online Anomaly Detection dataset -
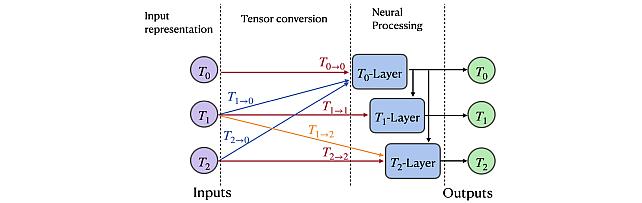
Group Representation Networks -
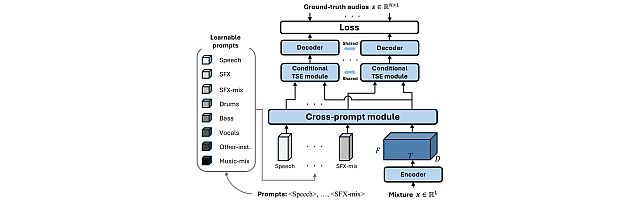
Task-Aware Unified Source Separation -
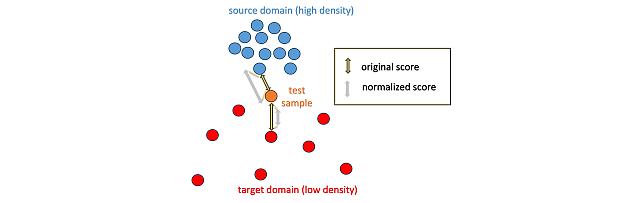
Local Density-Based Anomaly Score Normalization for Domain Generalization -
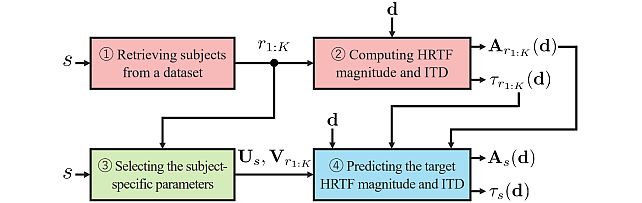
Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization -
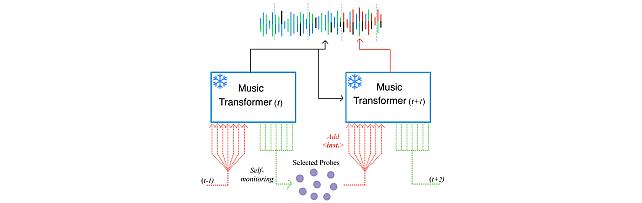
Self-Monitored Inference-Time INtervention for Generative Music Transformers -

MEL-PETs Defense for LLM Privacy Challenge -

MEL-PETs Joint-Context Attack for LLM Privacy Challenge -
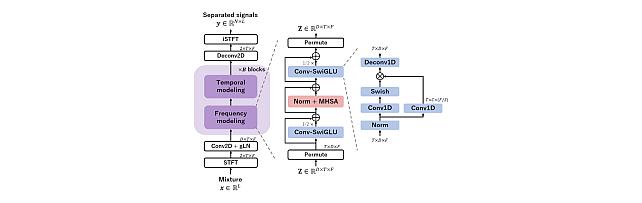
Transformer-based model with LOcal-modeling by COnvolution -
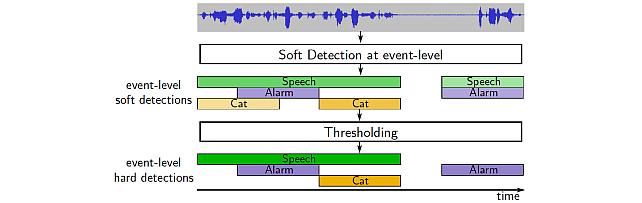
Sound Event Bounding Boxes -
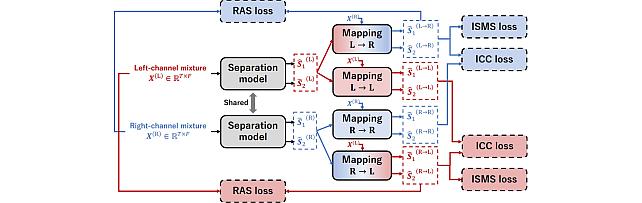
Enhanced Reverberation as Supervision -

Zero-Shot Image Conditioning for Text-to-Video Diffusion Models -
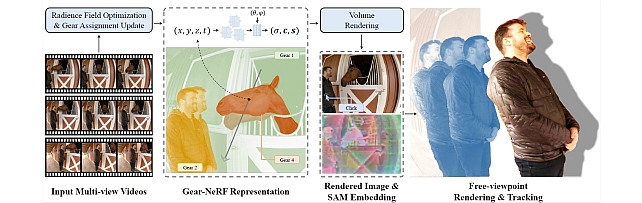
Gear Extensions of Neural Radiance Fields -
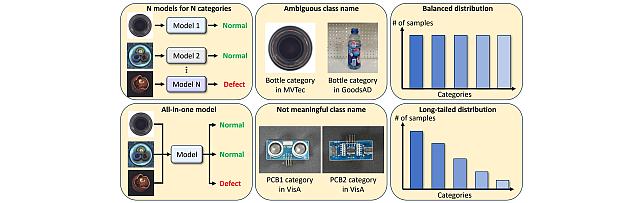
Long-Tailed Anomaly Detection Dataset -
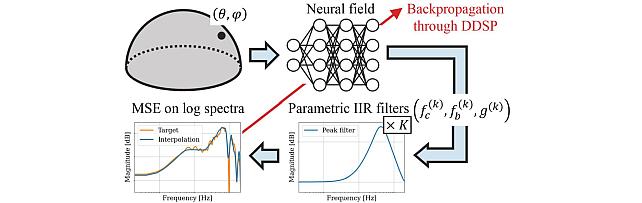
Neural IIR Filter Field for HRTF Upsampling and Personalization -
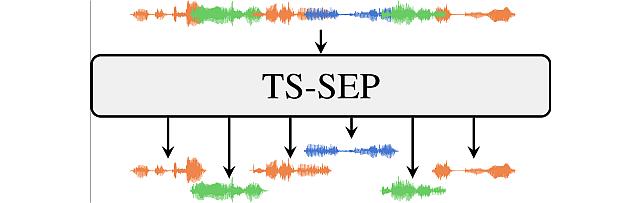
Target-Speaker SEParation -

Pixel-Grounded Prototypical Part Networks -

Steered Diffusion -
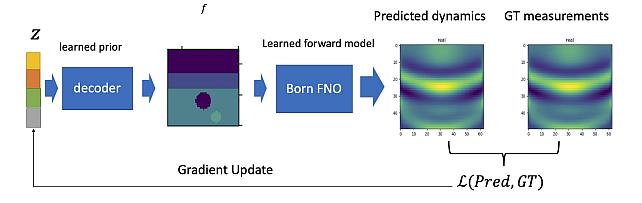
Learned Born Operator for Reflection Tomographic Imaging -
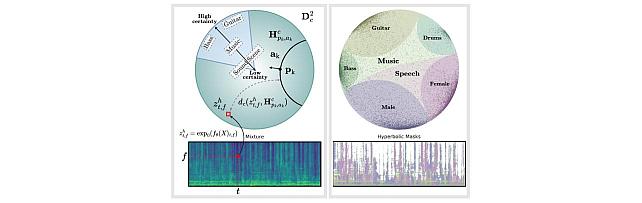
Hyperbolic Audio Source Separation -

Simple Multimodal Algorithmic Reasoning Task Dataset -
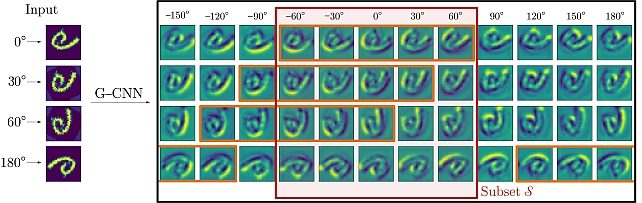
Partial Group Convolutional Neural Networks -
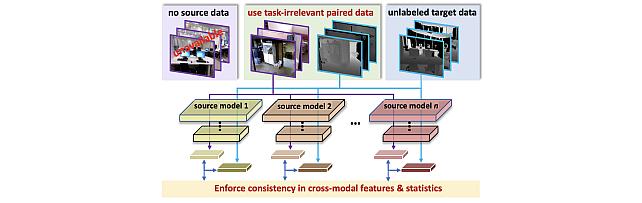
SOurce-free Cross-modal KnowledgE Transfer -
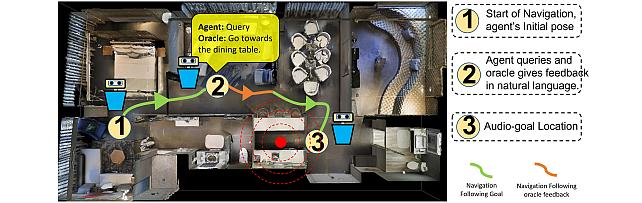
Audio-Visual-Language Embodied Navigation in 3D Environments -
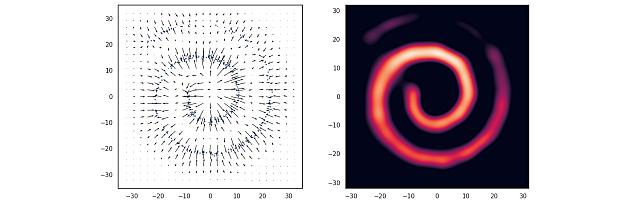
Nonparametric Score Estimators -

3D MOrphable STyleGAN -
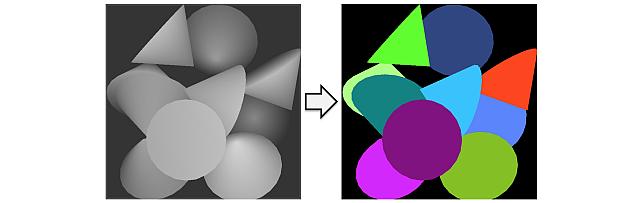
Instance Segmentation GAN -
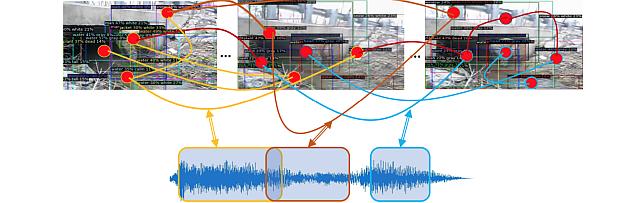
Audio Visual Scene-Graph Segmentor -
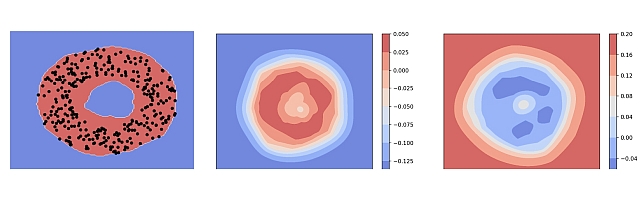
Generalized One-class Discriminative Subspaces -

Goal directed RL with Safety Constraints -
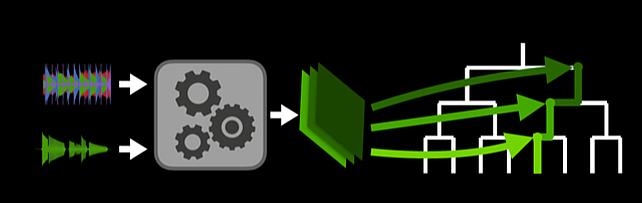
Hierarchical Musical Instrument Separation -

Generating Visual Dynamics from Sound and Context -

Adversarially-Contrastive Optimal Transport -
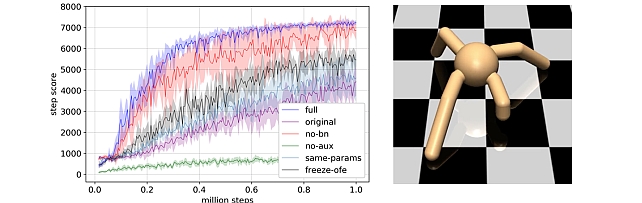
Online Feature Extractor Network -
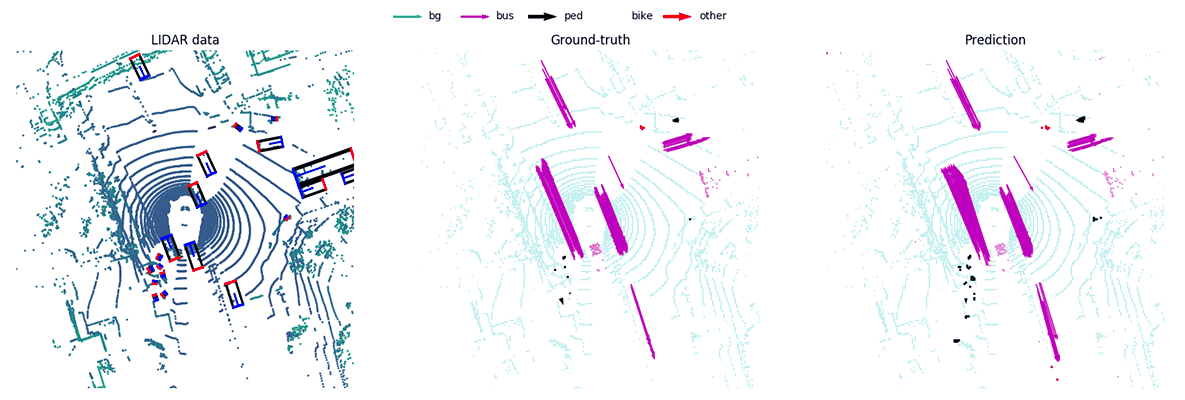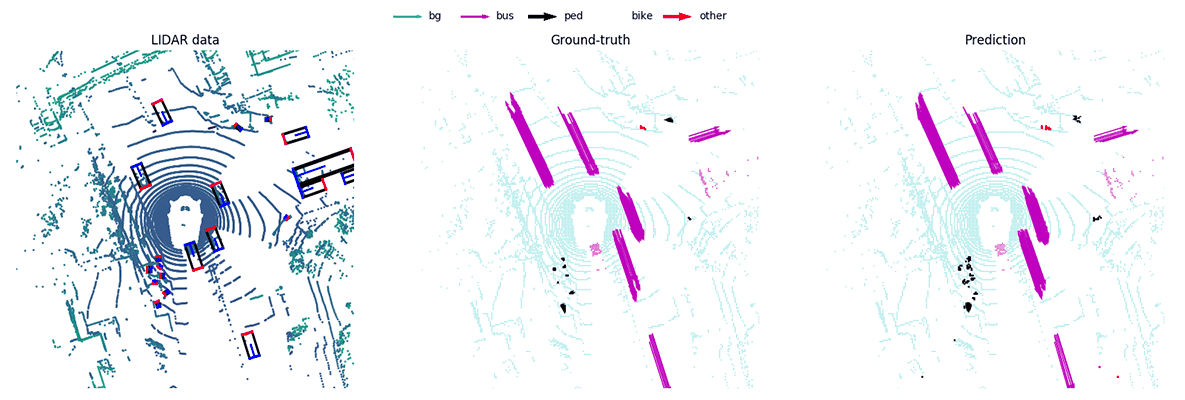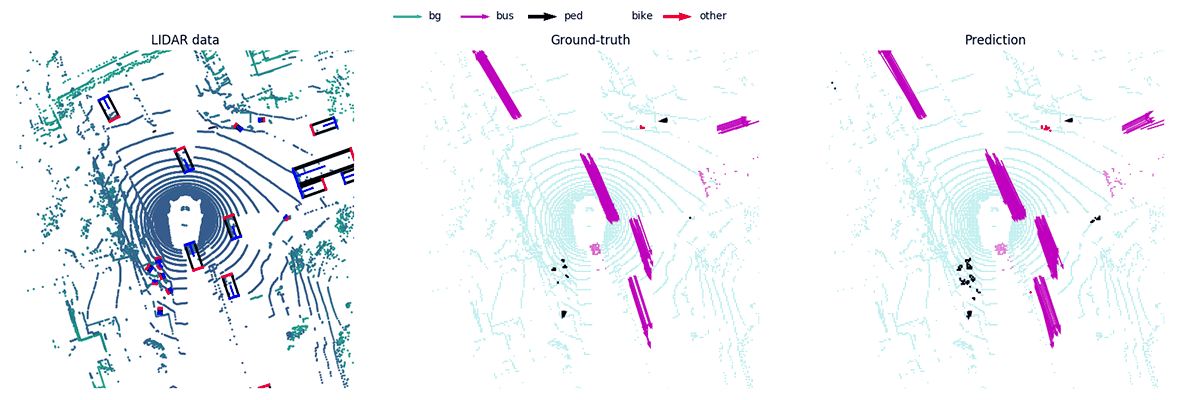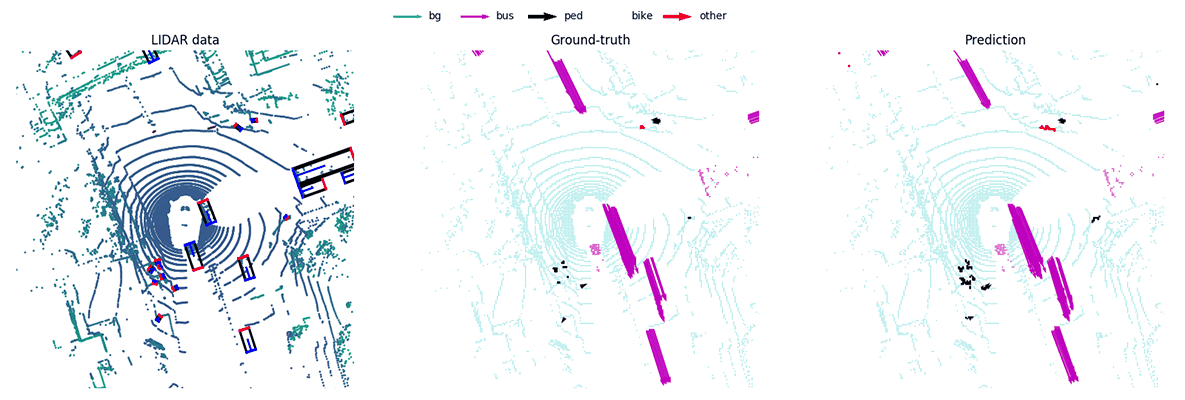
MotionNet -

FoldingNet++ -
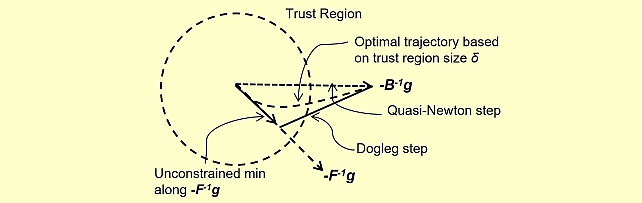
Quasi-Newton Trust Region Policy Optimization -
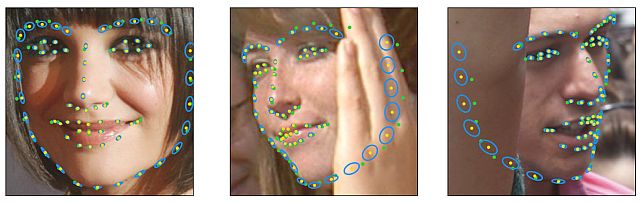
Landmarks’ Location, Uncertainty, and Visibility Likelihood -
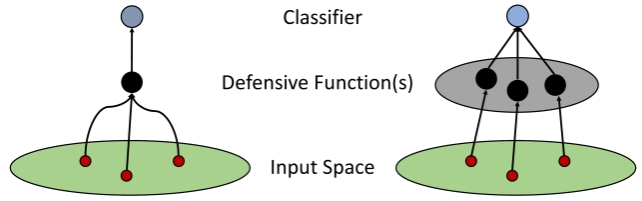
Robust Iterative Data Estimation -
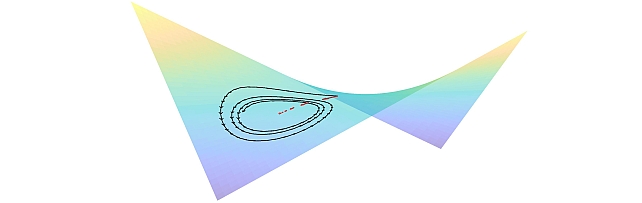
Gradient-based Nikaido-Isoda -

Discriminative Subspace Pooling
-