Tim K. Marks

- Phone: 617-621-7524
- Email:
-
Position:
Research / Technical Staff
Senior Principal Research Scientist,
Senior Team Leader -
Education:
Ph.D., University of California, San Diego, 2006 -
Research Areas:
- Computer Vision
- Artificial Intelligence
- Machine Learning
- Speech & Audio
- Robotics
- Signal Processing
- Human-Computer Interaction
External Links:
Tim's Quick Links
-
Biography
Prior to joining MERL's Imaging Group in 2008, Tim did postdoctoral research in robotic Simultaneous Localization and Mapping in collaboration with NASA's Jet Propulsion Laboratory. His research at MERL spans a variety of areas in computer vision and machine learning, including face recognition under variations in pose and lighting, and robotic vision and touch-based registration for industrial automation.
-
Recent News & Events
-
NEWS MERL Presents 7 Papers and 2 Workshops at CVPR 2026 Date: June 3, 2026 - June 7, 2026
Where: Colorado Convention Center, Denver, Colorado
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Kaen Kogashi; Suhas Lohit; Lalit Manam; Tim K. Marks; Pedro Miraldo; Kuan-Chuan Peng
Research Areas: Artificial Intelligence, Computer Vision, Machine LearningBrief- MERL researchers are proud to present 7 papers, including two highlight papers (top 3.6% of submissions), and 2 workshops at CVPR 2026. CVPR, taking place from June 3-7 in Denver, CO, USA, is a premier international conference in computer vision.
Papers with MERL Authors:
1. Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting by Xinhang Liu, Pedro Miraldo, Suhas Lohit, Huaizu Jiang, Naoko Sawada, Yu-Wing Tai, Chi-Keung Tang, and Moitreya Chatterjee (Highlight Paper)
2. Parallel Rigidity Matters for Bundle Adjustment by Lalit Manam and Venu Govindu (Highlight Paper)
3. Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling by Valter Piedade, Lalit Manam, Masashi Yamazaki, and Pedro Miraldo
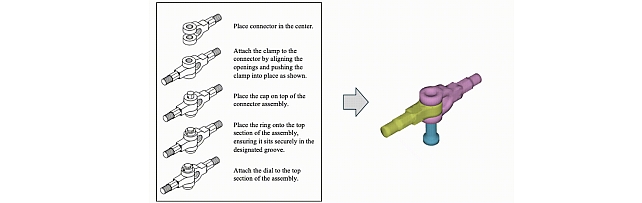
4. AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects by Danrui Li, Jiahao Zhang, Bernhard Egger, Moitreya Chatterjee, Suhas Lohit, Tim K. Marks, and Anoop Cherian
5. LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction by Tianye Ding, Yiming Xie, Yiqing Liang, Moitreya Chatterjee, Pedro Miraldo, and Huaizu Jiang
6. SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification by Jun-Wei Hsieh, Ying-Hsuan Wu, Yi-Kuan Hsieh, Xin Li, Kuan-Chuan Peng, Ming-Ching Chang (CVPR Findings paper)
7. MMHOI: Complex 3D Multi-Human-Object Interaction Understanding by Kaen Kogashi and Anoop Cherian (PhysHuman Workshop paper)
Workshops Co-Organized by MERL:
1. Multimodal Algorithmic Reasoning Workshop by Anoop Cherian, Suhas Lohit, Kuan-Chuan Peng, Honglu Zhou, Kevin Smith, and Josh Tenenbaum
2. The Third Workshop on Anomaly Detection with Foundation Models by Kuan-Chuan Peng, Ying Zhao, and Abhishek Aich
- MERL researchers are proud to present 7 papers, including two highlight papers (top 3.6% of submissions), and 2 workshops at CVPR 2026. CVPR, taking place from June 3-7 in Denver, CO, USA, is a premier international conference in computer vision.
-
NEWS MERL Papers, Workshops, and Talks at ICCV 2025 Date: October 19, 2025 - October 23, 2025
Where: Honolulu, HI, USA
MERL Contacts: Petros T. Boufounos; Anoop Cherian; Toshiaki Koike-Akino; Hassan Mansour; Tim K. Marks; Pedro Miraldo; Kuan-Chuan Peng; Pu (Perry) Wang
Research Areas: Artificial Intelligence, Computer Vision, Machine Learning, Signal ProcessingBrief- MERL researchers presented 3 conference papers and 3 workshop papers, co-organized 2 workshops, and delivered 2 invited talks at the IEEE International Conference on Computer Vision (ICCV) 2025, which was held in Honolulu, HI, USA from October 19-23, 2025. ICCV is one of the most prestigious and competitive international conferences in the area of computer vision. Details of MERL contributions are provided below:
Main Conference Papers:
1. "SAC-GNC: SAmple Consensus for adaptive Graduated Non-Convexity" by V. Piedade, C. Sidhartha, J. Gaspar, V. M. Govindu, and P. Miraldo. (Highlight Paper)
Paper: https://www.merl.com/publications/TR2025-146
2. "Toward Long-Tailed Online Anomaly Detection through Class-Agnostic Concepts" by C.-A. Yang, K.-C. Peng, and R. A. Yeh.
Paper: https://www.merl.com/publications/TR2025-124
3. "Manual-PA: Learning 3D Part Assembly from Instruction Diagrams" by J. Zhang, A. Cherian, C. Rodriguez-Opazo, W. Deng, and S. Gould.
Paper: https://www.merl.com/publications/TR2025-139
MERL Co-Organized Workshops:
1. "The Workshop on Anomaly Detection with Foundation Models (ADFM)" by K.-C. Peng, Y. Zhao, and A. Aich.
Workshop link: https://adfmw.github.io/iccv25/
2. "The 8th International Workshop on Computer Vision for Physiological Measurement (CVPM)" by D. McDuff, W. Wang, S. Stuijk, T. Marks, H. Mansour, V. R. Shenoy.
Workshop link: https://sstuijk.estue.nl/cvpm/cvpm25/
MERL Keynote Talks at Workshops:
1. Tim K. Marks, Keynote Speaker at the Workshop on Computer Vision for Physiological Measurement (CVPM).
Workshop website: https://vineetrshenoy.github.io/cvpmSeptember2025/
2. Tim K. Marks, Keynote Speaker at the Workshop on Analysis and Modeling of Faces and Gestures (AMFG).
Workshop website: https://fulab.sites.northeastern.edu/amfg2025/
Workshop Papers:
1. "Joint Training of Image Generator and Detector for Road Defect Detection" by K.-C. Peng.
paper: https://www.merl.com/publications/TR2025-149
2. "Radar-Conditioned 3D Bounding Box Diffusion for Indoor Human Perception" by R. Yataka, P. Wang, P.T. Boufounos, and R. Takahashi.
paper: https://www.merl.com/publications/TR2025-154
3. "L-GGSC: Learnable Graph-based Gaussian Splatting Compression" by S. Kato, T. Koike-Akino, and T. Fujihashi.
paper: https://www.merl.com/publications/TR2025-148
- MERL researchers presented 3 conference papers and 3 workshop papers, co-organized 2 workshops, and delivered 2 invited talks at the IEEE International Conference on Computer Vision (ICCV) 2025, which was held in Honolulu, HI, USA from October 19-23, 2025. ICCV is one of the most prestigious and competitive international conferences in the area of computer vision. Details of MERL contributions are provided below:
See All News & Events for Tim -
-
Awards
-
AWARD MERL Researchers win Best Paper Award at ICCV 2019 Workshop on Statistical Deep Learning in Computer Vision Date: October 27, 2019
Awarded to: Abhinav Kumar, Tim K. Marks, Wenxuan Mou, Chen Feng, Xiaoming Liu
MERL Contact: Tim K. Marks
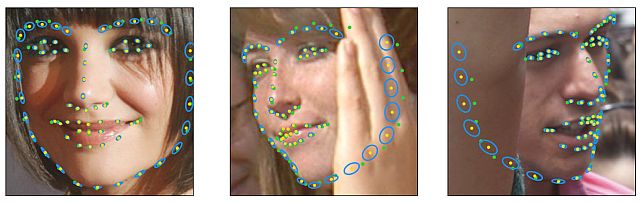
Research Areas: Artificial Intelligence, Computer Vision, Machine LearningBrief- MERL researcher Tim Marks, former MERL interns Abhinav Kumar and Wenxuan Mou, and MERL consultants Professor Chen Feng (NYU) and Professor Xiaoming Liu (MSU) received the Best Oral Paper Award at the IEEE/CVF International Conference on Computer Vision (ICCV) 2019 Workshop on Statistical Deep Learning in Computer Vision (SDL-CV) held in Seoul, Korea. Their paper, entitled "UGLLI Face Alignment: Estimating Uncertainty with Gaussian Log-Likelihood Loss," describes a method which, given an image of a face, estimates not only the locations of facial landmarks but also the uncertainty of each landmark location estimate.
-
-
Research Highlights
-
MERL Publications
- , "AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2026.BibTeX TR2026-076 PDF Video Data Software
- @inproceedings{Li2026jun,
- author = {Li, Danrui and Zhang, Jiahao and Egger, Bernhard and Chatterjee, Moitreya and Lohit, Suhas and Marks, Tim K. and Cherian, Anoop},
- title = {{AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-076}
- }
- , "Recovering Pulse Waves from Video Using Deep Unrolling and Deep Equilibrium Models", IEEE Transactions on Image Processing, DOI: 10.1109/TIP.2026.3671653, Vol. 35, pp. 2755-2770, March 2026.BibTeX TR2026-031 PDF
- @article{Shenoy2026mar,
- author = {Shenoy, Vineet and Lohit, Suhas and Mansour, Hassan and Chellappa, Rama and Marks, Tim K.},
- title = {{Recovering Pulse Waves from Video Using Deep Unrolling and Deep Equilibrium Models}},
- journal = {IEEE Transactions on Image Processing},
- year = 2026,
- volume = 35,
- pages = {2755--2770},
- month = mar,
- doi = {10.1109/TIP.2026.3671653},
- issn = {1941-0042},
- url = {https://www.merl.com/publications/TR2026-031}
- }
- , "Time-Series U-Net with Recurrence for Noise-Robust Imaging Photoplethysmography", IEEE Access, DOI: 10.1109/ACCESS.2025.3617284, Vol. 13, pp. 173923-173938, October 2025.BibTeX TR2025-145 PDF
- @article{Shenoy2025oct,
- author = {Shenoy, Vineet and Wu, Shaoju and Comas, Armand and Lohit, Suhas and Mansour, Hassan and Marks, Tim K.},
- title = {{Time-Series U-Net with Recurrence for Noise-Robust Imaging Photoplethysmography}},
- journal = {IEEE Access},
- year = 2025,
- volume = 13,
- pages = {173923--173938},
- month = oct,
- doi = {10.1109/ACCESS.2025.3617284},
- url = {https://www.merl.com/publications/TR2025-145}
- }
- , "Multimodal Diffusion Bridge with Attention-Based SAR Fusion for Satellite Image Cloud Removal", IEEE Transactions on Geoscience and Remote Sensing, DOI: 10.1109/TGRS.2025.3604654, Vol. 63, September 2025.BibTeX TR2025-138 PDF
- @article{Hu2025sep2,
- author = {Hu, Yuyang and Lohit, Suhas and Kamilov, Ulugbek and Marks, Tim K.},
- title = {{Multimodal Diffusion Bridge with Attention-Based SAR Fusion for Satellite Image Cloud Removal}},
- journal = {IEEE Transactions on Geoscience and Remote Sensing},
- year = 2025,
- volume = 63,
- month = sep,
- doi = {10.1109/TGRS.2025.3604654},
- issn = {1558-0644},
- url = {https://www.merl.com/publications/TR2025-138}
- }
- , "FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations", IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR), DOI: 10.1109/CVPRW67362.2025.00041, June 2025, pp. 369-379.BibTeX TR2025-074 PDF
- @inproceedings{Sawada2025jun,
- author = {Sawada, Naoko and Miraldo, Pedro and Lohit, Suhas and Marks, Tim K. and Chatterjee, Moitreya},
- title = {{FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR)},
- year = 2025,
- pages = {369--379},
- month = jun,
- doi = {10.1109/CVPRW67362.2025.00041},
- url = {https://www.merl.com/publications/TR2025-074}
- }
- , "AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2026.
-
Other Publications
- , "Gamma-SLAM: Visual SLAM in unstructured environments using variance grid maps", Journal of Field Robotics, Vol. 26, No. 1, pp. 26-51, 2009.BibTeX
- @Article{marks2009gamma,
- author = {Marks, Tim K and Howard, Andrew and Bajracharya, Max and Cottrell, Garrison W and Matthies, Larry H},
- title = {Gamma-SLAM: Visual SLAM in unstructured environments using variance grid maps},
- journal = {Journal of Field Robotics},
- year = 2009,
- volume = 26,
- number = 1,
- pages = {26--51},
- publisher = {Wiley Online Library}
- }
- , "NIMBLE: A kernel density model of saccade-based visual memory", Journal of Vision, Vol. 8, No. 14, 2008.BibTeX
- @Article{barrington2008nimble,
- author = {Barrington, Luke and Marks, Tim K and Hsiao, Janet Hui-wen and Cottrell, Garrison W},
- title = {NIMBLE: A kernel density model of saccade-based visual memory},
- journal = {Journal of Vision},
- year = 2008,
- volume = 8,
- number = 14,
- publisher = {Association for Research in Vision and Ophthalmology}
- }
- , "Gamma-SLAM: Using stereo vision and variance grid maps for SLAM in unstructured environments", Robotics and Automation, 2008. ICRA 2008. IEEE International Conference on, 2008, pp. 3717-3724.BibTeX
- @Inproceedings{marks2008gamma,
- author = {Marks, Tim K and Howard, Andrew and Bajracharya, Max and Cottrell, Garrison W and Matthies, Larry},
- title = {Gamma-SLAM: Using stereo vision and variance grid maps for SLAM in unstructured environments},
- booktitle = {Robotics and Automation, 2008. ICRA 2008. IEEE International Conference on},
- year = 2008,
- pages = {3717--3724},
- organization = {IEEE}
- }
- , "SUN: A Bayesian framework for saliency using natural statistics", Journal of Vision, Vol. 8, No. 7, 2008.BibTeX
- @Article{zhang2008sun,
- author = {Zhang, Lingyun and Tong, Matthew H and Marks, Tim K and Shan, Honghao and Cottrell, Garrison W},
- title = {SUN: A Bayesian framework for saliency using natural statistics},
- journal = {Journal of Vision},
- year = 2008,
- volume = 8,
- number = 7,
- publisher = {Association for Research in Vision and Ophthalmology}
- }
- , "Gamma-SLAM: Stereo visual SLAM in unstructured environments using variance grid maps", IROS visual SLAM workshop, 2007.BibTeX
- @Article{marks2007gamma,
- author = {Marks, Tim K and Howard, Andrew and Bajracharya, Max and Cottrell, Garrison W and Matthies, Larry},
- title = {Gamma-SLAM: Stereo visual SLAM in unstructured environments using variance grid maps},
- journal = {IROS visual SLAM workshop},
- year = 2007,
- publisher = {Citeseer}
- }
- , "Joint tracking of pose, expression, and texture using conditionally Gaussian filters", Advances in neural information processing systems, Vol. 17, pp. 889-896, 2005.BibTeX
- @Article{marks2005joint,
- author = {Marks, Tim K and Hershey, John and Roddey, J Cooper and Movellan, Javier R},
- title = {Joint tracking of pose, expression, and texture using conditionally Gaussian filters},
- journal = {Advances in neural information processing systems},
- year = 2005,
- volume = 17,
- pages = {889--896}
- }
- , "3d tracking of morphable objects using conditionally gaussian nonlinear filters", Computer Vision and Pattern Recognition Workshop, 2004. CVPRW'04. Conference on, 2004, pp. 190-190.BibTeX
- @Inproceedings{marks20043d,
- author = {Marks, Tim K and Hershey, John and Roddey, J Cooper and Movellan, Javier R},
- title = {3d tracking of morphable objects using conditionally gaussian nonlinear filters},
- booktitle = {Computer Vision and Pattern Recognition Workshop, 2004. CVPRW'04. Conference on},
- year = 2004,
- pages = {190--190},
- organization = {IEEE}
- }
- , "Diffusion networks, products of experts, and factor analysis", Proc. Int. Conf. on Independent Component Analysis, pp. 481-485, 2001.BibTeX
- @Article{marks2001diffusion,
- author = {Marks, Tim K and Movellan, Javier R},
- title = {Diffusion networks, products of experts, and factor analysis},
- journal = {Proc. Int. Conf. on Independent Component Analysis},
- year = 2001,
- pages = {481--485},
- publisher = {Citeseer}
- }
- , "Gamma-SLAM: Visual SLAM in unstructured environments using variance grid maps", Journal of Field Robotics, Vol. 26, No. 1, pp. 26-51, 2009.
-
Software & Data Downloads
-
Videos
-
MERL Issued Patents
-
Title: "System and Method for Generating Two-Dimensional (2D) Image of an Object in a Scene"
Inventors: Marks, Tim; Dey, Rahul; Egger, Bernhard; Wang, Ye
Patent No.: 12,675,919
Issue Date: Jul 7, 2026 -
Title: "Discriminative 3D Shape Modeling for Few-Shot Instance Segmentation"
Inventors: Cherian, Anoop; Sullivan, Alan; Marks, Tim
Patent No.: 12,406,374
Issue Date: Sep 2, 2025 -
Title: "System and Method for Remote Measurements of Vital Signs of a Person in a Volatile Environment"
Inventors: Marks, Tim; Mansour, Hassan; Nowara, Ewa; Nakamura, Yudai; Veeraraghavan, Ashok N.
Patent No.: 12,056,879
Issue Date: Aug 6, 2024 -
Title: "System and Method for Manipulating Two-Dimensional (2D) Images of Three-Dimensional (3D) Objects"
Inventors: Marks, Tim; Medin, Safa; Cherian, Anoop; Wang, Ye
Patent No.: 11,663,798
Issue Date: May 30, 2023 -
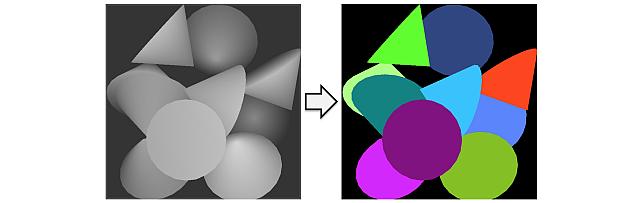
Title: "InSeGAN: A Generative Approach to Instance Segmentation in Depth Images"
Inventors: Cherian, Anoop; Pais, Goncalo; Marks, Tim; Sullivan, Alan
Patent No.: 11,651,497
Issue Date: May 16, 2023 -
Title: "Method and System for Scene-Aware Interaction"
Inventors: Hori, Chiori; Cherian, Anoop; Chen, Siheng; Marks, Tim; Le Roux, Jonathan; Hori, Takaaki; Harsham, Bret A.; Vetro, Anthony; Sullivan, Alan
Patent No.: 11,635,299
Issue Date: Apr 25, 2023 -
Title: "Scene-Aware Video Encoder System and Method"
Inventors: Cherian, Anoop; Hori, Chiori; Le Roux, Jonathan; Marks, Tim; Sullivan, Alan
Patent No.: 11,582,485
Issue Date: Feb 14, 2023 -
Title: "Low-latency Captioning System"
Inventors: Hori, Chiori; Hori, Takaaki; Cherian, Anoop; Marks, Tim; Le Roux, Jonathan
Patent No.: 11,445,267
Issue Date: Sep 13, 2022 -
Title: "System and Method for a Dialogue Response Generation System"
Inventors: Hori, Chiori; Cherian, Anoop; Marks, Tim; Hori, Takaaki
Patent No.: 11,264,009
Issue Date: Mar 1, 2022 -
Title: "System and Method for Remote Measurements of Vital Signs"
Inventors: Marks, Tim; Mansour, Hassan; Nowara, Ewa; Nakamura, Yudai; Veeraraghavan, Ashok N.
Patent No.: 11,259,710
Issue Date: Mar 1, 2022 -
Title: "Image Processing System and Method for Landmark Location Estimation with Uncertainty"
Inventors: Marks, Tim; Kumar, Abhinav; Mou, Wenxuan; Feng, Chen; Liu, Xiaoming
Patent No.: 11,127,164
Issue Date: Sep 21, 2021 -
Title: "Method and System for Determining 3D Object Poses and Landmark Points using Surface Patches"
Inventors: Jones, Michael J.; Marks, Tim; Papazov, Chavdar
Patent No.: 10,515,259
Issue Date: Dec 24, 2019 -
Title: "Method and System for Multi-Modal Fusion Model"
Inventors: Hori, Chiori; Hori, Takaaki; Hershey, John R.; Marks, Tim
Patent No.: 10,417,498
Issue Date: Sep 17, 2019 -
Title: "Method and System for Detecting Actions in Videos"
Inventors: Jones, Michael J.; Marks, Tim; Tuzel, Oncel; Singh, Bharat
Patent No.: 10,242,266
Issue Date: Mar 26, 2019 -
Title: "Method and System for Detecting Actions in Videos using Contour Sequences"
Inventors: Jones, Michael J.; Marks, Tim; Kulkarni, Kuldeep
Patent No.: 10,210,391
Issue Date: Feb 19, 2019 -
Title: "Method for Estimating Locations of Facial Landmarks in an Image of a Face using Globally Aligned Regression"
Inventors: Tuzel, Oncel; Marks, Tim; Tambe, Salil
Patent No.: 9,633,250
Issue Date: Apr 25, 2017 -
Title: "Method for Generating Representations Polylines Using Piecewise Fitted Geometric Primitives"
Inventors: Brand, Matthew E.; Marks, Tim; MV, Rohith
Patent No.: 9,613,443
Issue Date: Apr 4, 2017 -
Title: "Method for Determining Similarity of Objects Represented in Images"
Inventors: Jones, Michael J.; Marks, Tim; Ahmed, Ejaz
Patent No.: 9,436,895
Issue Date: Sep 6, 2016 -
Title: "Method for Detecting 3D Geometric Boundaries in Images of Scenes Subject to Varying Lighting"
Inventors: Marks, Tim; Tuzel, Oncel; Porikli, Fatih M.; Thornton, Jay E.; Ni, Jie
Patent No.: 9,418,434
Issue Date: Aug 16, 2016 -
Title: "Method for Factorizing Images of a Scene into Basis Images"
Inventors: Tuzel, Oncel; Marks, Tim; Porikli, Fatih M.; Ni, Jie
Patent No.: 9,384,553
Issue Date: Jul 5, 2016 -
Title: "Method and System for Tracking People in Indoor Environments using a Visible Light Camera and a Low-Frame-Rate Infrared Sensor"
Inventors: Marks, Tim; Jones, Michael J.; Kumar, Suren
Patent No.: 9,245,196
Issue Date: Jan 26, 2016 -
Title: "Method for Detecting and Tracking Objects in Image Sequences of Scenes Acquired by a Stationary Camera"
Inventors: Marks, Tim; Jones, Michael J.; MV, Rohith
Patent No.: 9,213,896
Issue Date: Dec 15, 2015 -
Title: "Method and System for Segmenting Moving Objects from Images Using Foreground Extraction"
Inventors: Veeraraghavan, Ashok N.; Marks, Tim; Taguchi, Yuichi
Patent No.: 8,941,726
Issue Date: Jan 27, 2015 -
Title: "Camera-Based 3D Climate Control"
Inventors: Marks, Tim; Jones, Michael J.
Patent No.: 8,929,592
Issue Date: Jan 6, 2015 -
Title: "Method and System for Registering an Object with a Probe Using Entropy-Based Motion Selection and Rao-Blackwellized Particle Filtering"
Inventors: Taguchi, Yuichi; Marks, Tim; Hershey, John R.
Patent No.: 8,510,078
Issue Date: Aug 13, 2013 -
Title: "Localization in Industrial Robotics Using Rao-Blackwellized Particle Filtering"
Inventors: Marks, Tim; Taguchi, Yuichi
Patent No.: 8,219,352
Issue Date: Jul 10, 2012 -
Title: "Method for Synthetically Images of Objects"
Inventors: Jones, Michael J.; Marks, Tim; Kumar, Ritwik
Patent No.: 8,194,072
Issue Date: Jun 5, 2012
-
Title: "System and Method for Generating Two-Dimensional (2D) Image of an Object in a Scene"