Moitreya Chatterjee

- Phone: 617-621-7592
- Email:
-
Position:
Research / Technical Staff
Research Scientist -
Education:
Ph.D., University of Illinois at Urbana-Champaign, 2022 -
Research Areas:
Moitreya's Quick Links
-
Biography
Moitreya's research interests are in computer vision, and multimodal machine learning with a particular emphasis on learning from audio-visual data. His PhD work received the Joan and Lalit Bahl Fellowship and the Thomas and Margaret Huang Research Award. Earlier, he earned a M.S. degree in Computer Science from the University of Southern California (USC), during which he received an Outstanding Paper Award from the ACM International Conference on Multimodal Interaction (ICMI).
-
Recent News & Events
-
NEWS MERL Presents 4 Main Conference Papers and 6 Workshop Papers at ICML 2026 Date: July 6, 2026 - July 11, 2026
Where: COEX, Seoul, South Korea
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Stefano Di Cairano; Toshiaki Koike-Akino; Christopher R. Laughman; Jing Liu; Suhas Lohit; Kuan-Chuan Peng; Alexander Schperberg; Ye Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Computer Vision, Machine Learning, Signal ProcessingBrief- MERL researchers are proud to present 4 main conference papers and 6 workshop papers at ICML 2026. ICML, taking place from July 6-11 in Seoul, South Korea, is a premier international conference in machine learning.
Main Conference Papers with MERL Authors:
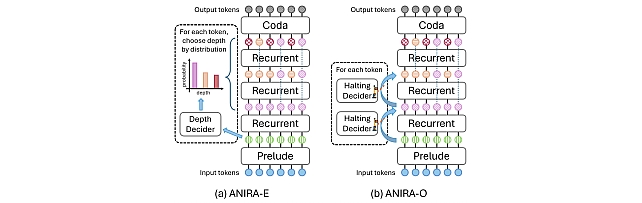
1. Understanding Dynamic Compute Allocation in Recurrent Transformers by Ibraheem Muhammad Moosa, Suhas Lohit, Ye Wang, Moitreya Chatterjee, and Wenpeng Yin.
2. LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior by Qinhong Zhou, Chuang Gan, and Anoop Cherian.
3. Memory-Distilled Selection for Noise-Robust Anomaly Detection by Sirojbek Safarov, Jaewoo Park, Yoon G. Jung, Kuan-Chuan Peng, Wonchul Kim, Seongdeok Bang, and Octavia Camps.
4. Partial Ring Scan: Revisiting Scan Order in Vision State Space Models by Yi-Kuan Hsieh, Kuan-Chuan Peng, Xin Li, Ming-Ching Chang, Yu-Chee Tseng, and Jun-Wei Hsieh.
Workshop Papers with MERL Authors:
1. WISE: Weighted Iterative Society-of-Experts for Multimodal Multi-Agent Debate with Probabilistic Consensus by Anoop Cherian, Suhas Lohit, and Kuan-Chuan Peng. (Workshop on Scalable Learning and Optimization for Efficient Multimodal AI Agents (SCALE))
2. MIRROR: Multisensory Implicit Rejection-sampled RObotic policy by Amisha Bhaskar, Pratap Tokekar, Stefano Di Cairano, and Alexander Schperberg. (Workshop on Structured Probabilistic Inference & Generative Modeling)
3. Reinforced Neural Processes: Memory-Efficient Time-Series Forecasting with a World-Feedback-Trained Memory Policy by Nibraas Khan, Gordon Wichern, and Christopher R. Laughman. (Workshop on Reinforcement Learning from World Feedback (RLxF))
4. Connecting Low-Rank Adapters and Policy Stability in GRPO Fine-Tuning by Antonin Rottman, Francesco Tonin, Yongtao Wu, Toshiaki Koike-Akino, and Volkan Cevher. (Workshop on Connecting Low-rank Representations in AI (CoLorAI))
5. EinSort: Sorting is All We Need for Tensorizing LLM by Toshiaki Koike-Akino, Jing Liu, and Ye Wang. (Workshop on Connecting Low-rank Representations in AI (CoLorAI))
6. Temper and Tilt Lead to SLOP: Reward Hacking Mitigation with Inference-Time Alignment by Ye Wang, and Jing Liu, and Toshiaki Koike-Akino. (Workshop on Agents in the Wild: Safety, Security, and Beyond)
- MERL researchers are proud to present 4 main conference papers and 6 workshop papers at ICML 2026. ICML, taking place from July 6-11 in Seoul, South Korea, is a premier international conference in machine learning.
-
NEWS MERL Presents 7 Papers and 2 Workshops at CVPR 2026 Date: June 3, 2026 - June 7, 2026
Where: Colorado Convention Center, Denver, Colorado
MERL Contacts: Moitreya Chatterjee; Anoop Cherian; Kaen Kogashi; Suhas Lohit; Lalit Manam; Tim K. Marks; Pedro Miraldo; Kuan-Chuan Peng
Research Areas: Artificial Intelligence, Computer Vision, Machine LearningBrief- MERL researchers are proud to present 7 papers, including two highlight papers (top 3.6% of submissions), and 2 workshops at CVPR 2026. CVPR, taking place from June 3-7 in Denver, CO, USA, is a premier international conference in computer vision.
Papers with MERL Authors:
1. Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting by Xinhang Liu, Pedro Miraldo, Suhas Lohit, Huaizu Jiang, Naoko Sawada, Yu-Wing Tai, Chi-Keung Tang, and Moitreya Chatterjee (Highlight Paper)
2. Parallel Rigidity Matters for Bundle Adjustment by Lalit Manam and Venu Govindu (Highlight Paper)
3. Revisiting Monocular SLAM with Spatio-Temporal Scene Modeling by Valter Piedade, Lalit Manam, Masashi Yamazaki, and Pedro Miraldo
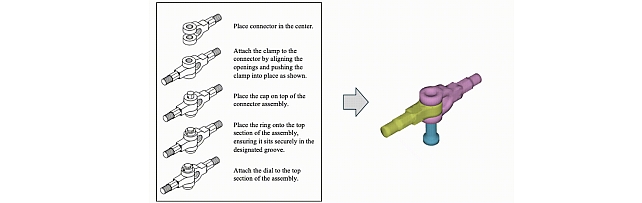
4. AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects by Danrui Li, Jiahao Zhang, Bernhard Egger, Moitreya Chatterjee, Suhas Lohit, Tim K. Marks, and Anoop Cherian
5. LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction by Tianye Ding, Yiming Xie, Yiqing Liang, Moitreya Chatterjee, Pedro Miraldo, and Huaizu Jiang
6. SoREL: Soft-Label Refurbishment with Ensemble Learning for Noisy Long-Tailed Classification by Jun-Wei Hsieh, Ying-Hsuan Wu, Yi-Kuan Hsieh, Xin Li, Kuan-Chuan Peng, Ming-Ching Chang (CVPR Findings paper)
7. MMHOI: Complex 3D Multi-Human-Object Interaction Understanding by Kaen Kogashi and Anoop Cherian (PhysHuman Workshop paper)
Workshops Co-Organized by MERL:
1. Multimodal Algorithmic Reasoning Workshop by Anoop Cherian, Suhas Lohit, Kuan-Chuan Peng, Honglu Zhou, Kevin Smith, and Josh Tenenbaum
2. The Third Workshop on Anomaly Detection with Foundation Models by Kuan-Chuan Peng, Ying Zhao, and Abhishek Aich
- MERL researchers are proud to present 7 papers, including two highlight papers (top 3.6% of submissions), and 2 workshops at CVPR 2026. CVPR, taking place from June 3-7 in Denver, CO, USA, is a premier international conference in computer vision.
See All News & Events for Moitreya -
-
Research Highlights
-
Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting -
AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects -
PS-NeuS: A Probability-guided Sampler for Neural Implicit Surface Rendering -
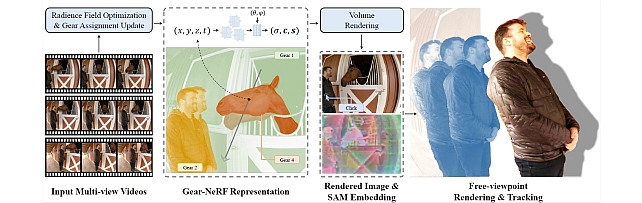
Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-Aware Spatio-Temporal Sampling
-
-
MERL Publications
- , "Understanding Dynamic Compute Allocation in Recurrent Transformers", International Conference on Machine Learning (ICML), July 2026.BibTeX TR2026-090 PDF Software Presentation
- @inproceedings{Moosa2026jul,
- author = {{Moosa, Ibraheem Muhammad and Lohit, Suhas and Wang, Ye and Chatterjee, Moitreya and Yin, Wenpeng}},
- title = {{Understanding Dynamic Compute Allocation in Recurrent Transformers}},
- booktitle = {International Conference on Machine Learning (ICML)},
- year = 2026,
- month = jul,
- url = {https://www.merl.com/publications/TR2026-090}
- }
- , "AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2026.BibTeX TR2026-076 PDF Video Data Software
- @inproceedings{Li2026jun,
- author = {Li, Danrui and Zhang, Jiahao and Egger, Bernhard and Chatterjee, Moitreya and Lohit, Suhas and Marks, Tim K. and Cherian, Anoop},
- title = {{AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-076}
- }
- , "Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2026.BibTeX TR2026-077 PDF
- @inproceedings{Liu2026jun,
- author = {Liu, Xinhang and Miraldo, Pedro and Lohit, Suhas and Jiang, Huaizu and Sawada, Naoko and Tai, Yu-Wing and Tang, Chi-Keung and Chatterjee, Moitreya},
- title = {{Point4Cast: Streaming Dynamic Scene Reconstruction and Forecasting}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = jun,
- url = {https://www.merl.com/publications/TR2026-077}
- }
- , "LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), May 2026.BibTeX TR2026-055 PDF
- @inproceedings{Ding2026may,
- author = {Ding, Tianye and Xie, Yiming and Liang, Yiqing and Chatterjee, Moitreya and Miraldo, Pedro and Jiang, Huaizu},
- title = {{LASER: Layer-wise Scale Alignment for Training-Free Streaming 4D Reconstruction}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2026,
- month = may,
- url = {https://www.merl.com/publications/TR2026-055}
- }
- , "UWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), DOI: 10.1109/CVPR52734.2025.01266, June 2025, pp. 13561-13570.BibTeX TR2025-072 PDF
- @inproceedings{Lai2025jun,
- author = {Lai, Yung-Hsuan and Ebbers, Janek and Wang, Yu-Chiang Frank and Germain, François G and Jones, Michael J. and Chatterjee, Moitreya},
- title = {{UWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing}},
- booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = 2025,
- pages = {13561--13570},
- month = jun,
- publisher = {IEEE},
- doi = {10.1109/CVPR52734.2025.01266},
- url = {https://www.merl.com/publications/TR2025-072}
- }
- , "Understanding Dynamic Compute Allocation in Recurrent Transformers", International Conference on Machine Learning (ICML), July 2026.
-
Other Publications
- , "A hierarchical variational neural uncertainty model for stochastic video prediction", Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9751-9761.BibTeX
- @Inproceedings{chatterjee2021hierarchical,
- author = {Chatterjee, Moitreya and Ahuja, Narendra and Cherian, Anoop},
- title = {A hierarchical variational neural uncertainty model for stochastic video prediction},
- booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
- year = 2021,
- pages = {9751--9761}
- }
- , "Visual scene graphs for audio source separation", Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1204-1213.BibTeX
- @Inproceedings{chatterjee2021visual,
- author = {Chatterjee, Moitreya and Le Roux, Jonathan and Ahuja, Narendra and Cherian, Anoop},
- title = {Visual scene graphs for audio source separation},
- booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
- year = 2021,
- pages = {1204--1213}
- }
- , "Dynamic graph representation learning for video dialog via multi-modal shuffled transformers", Proceedings of the AAAI Conference on Artificial Intelligence, 2021, vol. 35, pp. 1415-1423.BibTeX
- @Inproceedings{geng2021dynamic,
- author = {Geng, Shijie and Gao, Peng and Chatterjee, Moitreya and Hori, Chiori and Le Roux, Jonathan and Zhang, Yongfeng and Li, Hongsheng and Cherian, Anoop},
- title = {Dynamic graph representation learning for video dialog via multi-modal shuffled transformers},
- booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence},
- year = 2021,
- volume = 35,
- number = 2,
- pages = {1415--1423}
- }
- , "Sound2sight: Generating visual dynamics from sound and context", European Conference on Computer Vision, 2020, pp. 701-719.BibTeX
- @Inproceedings{chatterjee2020sound2sight,
- author = {Chatterjee, Moitreya and Cherian, Anoop},
- title = {Sound2sight: Generating visual dynamics from sound and context},
- booktitle = {European Conference on Computer Vision},
- year = 2020,
- pages = {701--719},
- organization = {Springer}
- }
- , "Coreset-based neural network compression", Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 454-470.BibTeX
- @Inproceedings{dubey2018coreset,
- author = {Dubey, Abhimanyu and Chatterjee, Moitreya and Ahuja, Narendra},
- title = {Coreset-based neural network compression},
- booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
- year = 2018,
- pages = {454--470}
- }
- , "Deep neural networks with inexact matching for person re-identification", Advances in neural information processing systems, Vol. 29, 2016.BibTeX
- @Article{subramaniam2016deep,
- author = {Subramaniam, Arulkumar and Chatterjee, Moitreya and Mittal, Anurag},
- title = {Deep neural networks with inexact matching for person re-identification},
- journal = {Advances in neural information processing systems},
- year = 2016,
- volume = 29
- }
- , "Combining two perspectives on classifying multimodal data for recognizing speaker traits", Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, 2015, pp. 7-14.BibTeX
- @Inproceedings{chatterjee2015combining,
- author = {Chatterjee, Moitreya and Park, Sunghyun and Morency, Louis-Philippe and Scherer, Stefan},
- title = {Combining two perspectives on classifying multimodal data for recognizing speaker traits},
- booktitle = {Proceedings of the 2015 ACM on International Conference on Multimodal Interaction},
- year = 2015,
- pages = {7--14}
- }
- , "A hierarchical variational neural uncertainty model for stochastic video prediction", Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9751-9761.
-
Software & Data Downloads
-
Videos
-
MERL Issued Patents
-
Title: "NEURAL RADIANCE FIELD TRAINING BASED ON A NON-UNIFORM SAMPLE OF IMAGE PIXELS"
Inventors: Miraldo, Pedro; Greiff, Marcus; Pais, Goncalo; Chatterjee, Moitreya
Patent No.: 12,633,035
Issue Date: May 19, 2026 -
Title: "Rendering Two-Dimensional Image of a Dynamic Three-Dimensional Scene"
Inventors: Chatterjee, Moitreya; Lohit, Suhas; Miraldo, Pedro
Patent No.: 12,475,636
Issue Date: Nov 18, 2025 -
Title: "System and Method for Controlling a Robot"
Inventors: Cherian, Anoop; Chatterjee, Moitreya; Liu, Xiulong; Paul, Sudipta
Patent No.: 12/459/115
Issue Date: Nov 4, 2025 -
Title: "A Method and System for Scene-Aware Audio-Video Representation"
Inventors: Cherian, Anoop; Chatterjee, Moitreya; Le Roux, Jonathan
Patent No.: 12,056,213
Issue Date: Aug 6, 2024
-
Title: "NEURAL RADIANCE FIELD TRAINING BASED ON A NON-UNIFORM SAMPLE OF IMAGE PIXELS"