François Germain

- Phone: 617-621-7506
- Email:
-
Position:
Research / Technical Staff
Visiting Research Scientist -
Education:
Ph.D., Stanford University, 2019 -
Research Areas:
François' Quick Links
-
Biography
During his graduate studies, François worked on advancing the state of the art in efficient modelling of analog audio systems. Concurrently, he made important contributions to audio signal processing and spatial audio rendering during internships at Adobe Research, Dolby Laboratories and Intel Labs. Before joining MERL, he led research on music source separation and speech enhancement at iZotope. His research interests focus on efficient and robust signal processing and machine learning methods applied to speech, music, and audio content in general.
-
Recent News & Events
-
NEWS MERL Papers and Workshops at CVPR 2025 Date: June 11, 2025 - June 15, 2025
Where: Nashville, TN, USA
MERL Contacts: Matthew Brand; Moitreya Chatterjee; Anoop Cherian; François Germain; Michael J. Jones; Toshiaki Koike-Akino; Jing Liu; Suhas Lohit; Tim K. Marks; Pedro Miraldo; Kuan-Chuan Peng; Pu (Perry) Wang; Ye Wang
Research Areas: Artificial Intelligence, Computer Vision, Machine Learning, Signal Processing, Speech & AudioBrief- MERL researchers are presenting 2 conference papers, co-organizing two workshops, and presenting 7 workshop papers at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2025 conference, which will be held in Nashville, TN, USA from June 11-15, 2025. CVPR is one of the most prestigious and competitive international conferences in the area of computer vision. Details of MERL contributions are provided below:
Main Conference Papers:
1. "UWAV: Uncertainty-weighted Weakly-supervised Audio-Visual Video Parsing" by Y.H. Lai, J. Ebbers, Y. F. Wang, F. Germain, M. J. Jones, M. Chatterjee
This work deals with the task of weakly‑supervised Audio-Visual Video Parsing (AVVP) and proposes a novel, uncertainty-aware algorithm called UWAV towards that end. UWAV works by producing more reliable segment‑level pseudo‑labels while explicitly weighting each label by its prediction uncertainty. This uncertainty‑aware training, combined with a feature‑mixup regularization scheme, promotes inter‑segment consistency in the pseudo-labels. As a result, UWAV achieves state‑of‑the‑art performance on two AVVP datasets across multiple metrics, demonstrating both effectiveness and strong generalizability.
Paper: https://www.merl.com/publications/TR2025-072
2. "TailedCore: Few-Shot Sampling for Unsupervised Long-Tail Noisy Anomaly Detection" by Y. G. Jung, J. Park, J. Yoon, K.-C. Peng, W. Kim, A. B. J. Teoh, and O. Camps.
This work tackles unsupervised anomaly detection in complex scenarios where normal data is noisy and has an unknown, imbalanced class distribution. Existing models face a trade-off between robustness to noise and performance on rare (tail) classes. To address this, the authors propose TailSampler, which estimates class sizes from embedding similarities to isolate tail samples. Using TailSampler, they develop TailedCore, a memory-based model that effectively captures tail class features while remaining noise-robust, outperforming state-of-the-art methods in extensive evaluations.
paper: https://www.merl.com/publications/TR2025-077
MERL Co-Organized Workshops:
1. Multimodal Algorithmic Reasoning (MAR) Workshop, organized by A. Cherian, K.-C. Peng, S. Lohit, H. Zhou, K. Smith, L. Xue, T. K. Marks, and J. Tenenbaum.
Workshop link: https://marworkshop.github.io/cvpr25/
2. The 6th Workshop on Fair, Data-Efficient, and Trusted Computer Vision, organized by N. Ratha, S. Karanam, Z. Wu, M. Vatsa, R. Singh, K.-C. Peng, M. Merler, and K. Varshney.
Workshop link: https://fadetrcv.github.io/2025/
Workshop Papers:
1. "FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations" by N. Sawada, P. Miraldo, S. Lohit, T.K. Marks, and M. Chatterjee (Oral)
With their ability to model object surfaces in a scene as a continuous function, neural implicit surface reconstruction methods have made remarkable strides recently, especially over classical 3D surface reconstruction methods, such as those that use voxels or point clouds. Towards this end, we propose FreBIS - a neural implicit‑surface framework that avoids overloading a single encoder with every surface detail. It divides a scene into several frequency bands and assigns a dedicated encoder (or group of encoders) to each band, then enforces complementary feature learning through a redundancy‑aware weighting module. Swapping this frequency‑stratified stack into an off‑the‑shelf reconstruction pipeline markedly boosts 3D surface accuracy and view‑consistent rendering on the challenging BlendedMVS dataset.
paper: https://www.merl.com/publications/TR2025-074
2. "Multimodal 3D Object Detection on Unseen Domains" by D. Hegde, S. Lohit, K.-C. Peng, M. J. Jones, and V. M. Patel.
LiDAR-based object detection models often suffer performance drops when deployed in unseen environments due to biases in data properties like point density and object size. Unlike domain adaptation methods that rely on access to target data, this work tackles the more realistic setting of domain generalization without test-time samples. We propose CLIX3D, a multimodal framework that uses both LiDAR and image data along with supervised contrastive learning to align same-class features across domains and improve robustness. CLIX3D achieves state-of-the-art performance across various domain shifts in 3D object detection.
paper: https://www.merl.com/publications/TR2025-078
3. "Improving Open-World Object Localization by Discovering Background" by A. Singh, M. J. Jones, K.-C. Peng, M. Chatterjee, A. Cherian, and E. Learned-Miller.
This work tackles open-world object localization, aiming to detect both seen and unseen object classes using limited labeled training data. While prior methods focus on object characterization, this approach introduces background information to improve objectness learning. The proposed framework identifies low-information, non-discriminative image regions as background and trains the model to avoid generating object proposals there. Experiments on standard benchmarks show that this method significantly outperforms previous state-of-the-art approaches.
paper: https://www.merl.com/publications/TR2025-058
4. "PF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector" by K. Li, T. Zhang, K.-C. Peng, and G. Wang.
This work addresses challenges in 3D object detection for autonomous driving by improving the fusion of LiDAR and camera data, which is often hindered by domain gaps and limited labeled data. Leveraging advances in foundation models and prompt engineering, the authors propose PF3Det, a multi-modal detector that uses foundation model encoders and soft prompts to enhance feature fusion. PF3Det achieves strong performance even with limited training data. It sets new state-of-the-art results on the nuScenes dataset, improving NDS by 1.19% and mAP by 2.42%.
paper: https://www.merl.com/publications/TR2025-076
5. "Noise Consistency Regularization for Improved Subject-Driven Image Synthesis" by Y. Ni., S. Wen, P. Konius, A. Cherian
Fine-tuning Stable Diffusion enables subject-driven image synthesis by adapting the model to generate images containing specific subjects. However, existing fine-tuning methods suffer from two key issues: underfitting, where the model fails to reliably capture subject identity, and overfitting, where it memorizes the subject image and reduces background diversity. To address these challenges, two auxiliary consistency losses are porposed for diffusion fine-tuning. First, a prior consistency regularization loss ensures that the predicted diffusion noise for prior (non- subject) images remains consistent with that of the pretrained model, improving fidelity. Second, a subject consistency regularization loss enhances the fine-tuned model’s robustness to multiplicative noise modulated latent code, helping to preserve subject identity while improving diversity. Our experimental results demonstrate the effectiveness of our approach in terms of image diversity, outperforming DreamBooth in terms of CLIP scores, background variation, and overall visual quality.
paper: https://www.merl.com/publications/TR2025-073
6. "LatentLLM: Attention-Aware Joint Tensor Compression" by T. Koike-Akino, X. Chen, J. Liu, Y. Wang, P. Wang, M. Brand
We propose a new framework to convert a large foundation model such as large language models (LLMs)/large multi- modal models (LMMs) into a reduced-dimension latent structure. Our method uses a global attention-aware joint tensor decomposition to significantly improve the model efficiency. We show the benefit on several benchmark including multi-modal reasoning tasks.
paper: https://www.merl.com/publications/TR2025-075
7. "TuneComp: Joint Fine-Tuning and Compression for Large Foundation Models" by T. Koike-Akino, X. Chen, J. Liu, Y. Wang, P. Wang, M. Brand
To reduce model size during post-training, compression methods, including knowledge distillation, low-rank approximation, and pruning, are often applied after fine- tuning the model. However, sequential fine-tuning and compression sacrifices performance, while creating a larger than necessary model as an intermediate step. In this work, we aim to reduce this gap, by directly constructing a smaller model while guided by the downstream task. We propose to jointly fine-tune and compress the model by gradually distilling it to a pruned low-rank structure. Experiments demonstrate that joint fine-tuning and compression significantly outperforms other sequential compression methods.
paper: https://www.merl.com/publications/TR2025-079
- MERL researchers are presenting 2 conference papers, co-organizing two workshops, and presenting 7 workshop papers at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2025 conference, which will be held in Nashville, TN, USA from June 11-15, 2025. CVPR is one of the most prestigious and competitive international conferences in the area of computer vision. Details of MERL contributions are provided below:
-
EVENT MERL Contributes to ICASSP 2025 Date: Sunday, April 6, 2025 - Friday, April 11, 2025
Location: Hyderabad, India
MERL Contacts: Wael H. Ali; Petros T. Boufounos; Radu Corcodel; François Germain; Chiori Hori; Siddarth Jain; Devesh K. Jha; Toshiaki Koike-Akino; Jonathan Le Roux; Yanting Ma; Hassan Mansour; Yoshiki Masuyama; Joshua Rapp; Diego Romeres; Anthony Vetro; Pu (Perry) Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Communications, Computational Sensing, Electronic and Photonic Devices, Machine Learning, Robotics, Signal Processing, Speech & AudioBrief- MERL has made numerous contributions to both the organization and technical program of ICASSP 2025, which is being held in Hyderabad, India from April 6-11, 2025.
Sponsorship
MERL is proud to be a Silver Patron of the conference and will participate in the student job fair on Thursday, April 10. Please join this session to learn more about employment opportunities at MERL, including openings for research scientists, post-docs, and interns.
MERL is pleased to be the sponsor of two IEEE Awards that will be presented at the conference. We congratulate Prof. Björn Erik Ottersten, the recipient of the 2025 IEEE Fourier Award for Signal Processing, and Prof. Shrikanth Narayanan, the recipient of the 2025 IEEE James L. Flanagan Speech and Audio Processing Award. Both awards will be presented in-person at ICASSP by Anthony Vetro, MERL President & CEO.
Technical Program
MERL is presenting 15 papers in the main conference on a wide range of topics including source separation, sound event detection, sound anomaly detection, speaker diarization, music generation, robot action generation from video, indoor airflow imaging, WiFi sensing, Doppler single-photon Lidar, optical coherence tomography, and radar imaging. Another paper on spatial audio will be presented at the Generative Data Augmentation for Real-World Signal Processing Applications (GenDA) Satellite Workshop.
MERL Researchers Petros Boufounos and Hassan Mansour will present a Tutorial on “Computational Methods in Radar Imaging” in the afternoon of Monday, April 7.
Petros Boufounos will also be giving an industry talk on Thursday April 10 at 12pm, on “A Physics-Informed Approach to Sensing".
About ICASSP
ICASSP is the flagship conference of the IEEE Signal Processing Society, and the world's largest and most comprehensive technical conference focused on the research advances and latest technological development in signal and information processing. The event has been attracting more than 4000 participants each year.
- MERL has made numerous contributions to both the organization and technical program of ICASSP 2025, which is being held in Hyderabad, India from April 6-11, 2025.
See All News & Events for François -
-
Awards
-
AWARD MERL team wins the Listener Acoustic Personalisation (LAP) 2024 Challenge Date: August 29, 2024
Awarded to: Yoshiki Masuyama, Gordon Wichern, Francois G. Germain, Christopher Ick, and Jonathan Le Roux
MERL Contacts: François Germain; Jonathan Le Roux; Gordon Wichern; Yoshiki Masuyama
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 7 teams in Task 2 of the 1st SONICOM Listener Acoustic Personalisation (LAP) Challenge, which focused on "Spatial upsampling for obtaining a high-spatial-resolution HRTF from a very low number of directions". The team was led by Yoshiki Masuyama, and also included Gordon Wichern, Francois Germain, MERL intern Christopher Ick, and Jonathan Le Roux.
The LAP Challenge workshop and award ceremony was hosted by the 32nd European Signal Processing Conference (EUSIPCO 24) on August 29, 2024 in Lyon, France. Yoshiki Masuyama presented the team's method, "Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization", and received the award from Prof. Michele Geronazzo (University of Padova, IT, and Imperial College London, UK), Chair of the Challenge's Organizing Committee.
The LAP challenge aims to explore challenges in the field of personalized spatial audio, with the first edition focusing on the spatial upsampling and interpolation of head-related transfer functions (HRTFs). HRTFs with dense spatial grids are required for immersive audio experiences, but their recording is time-consuming. Although HRTF spatial upsampling has recently shown remarkable progress with approaches involving neural fields, HRTF estimation accuracy remains limited when upsampling from only a few measured directions, e.g., 3 or 5 measurements. The MERL team tackled this problem by proposing a retrieval-augmented neural field (RANF). RANF retrieves a subject whose HRTFs are close to those of the target subject at the measured directions from a library of subjects. The HRTF of the retrieved subject at the target direction is fed into the neural field in addition to the desired sound source direction. The team also developed a neural network architecture that can handle an arbitrary number of retrieved subjects, inspired by a multi-channel processing technique called transform-average-concatenate.
- MERL's Speech & Audio team ranked 1st out of 7 teams in Task 2 of the 1st SONICOM Listener Acoustic Personalisation (LAP) Challenge, which focused on "Spatial upsampling for obtaining a high-spatial-resolution HRTF from a very low number of directions". The team was led by Yoshiki Masuyama, and also included Gordon Wichern, Francois Germain, MERL intern Christopher Ick, and Jonathan Le Roux.
-
AWARD MERL team wins the Audio-Visual Speech Enhancement (AVSE) 2023 Challenge Date: December 16, 2023
Awarded to: Zexu Pan, Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux
MERL Contacts: François Germain; Chiori Hori; Jonathan Le Roux; Gordon Wichern; Yoshiki Masuyama
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
The AVSE challenge aims to design better speech enhancement systems by harnessing the visual aspects of speech (such as lip movements and gestures) in a manner similar to the brain’s multi-modal integration strategies. MERL’s system was a scenario-aware audio-visual TF-GridNet, that incorporates the face recording of a target speaker as a conditioning factor and also recognizes whether the predominant interference signal is speech or background noise. In addition to outperforming all competing systems in terms of objective metrics by a wide margin, in a listening test, MERL’s model achieved the best overall word intelligibility score of 84.54%, compared to 57.56% for the baseline and 80.41% for the next best team. The Fisher’s least significant difference (LSD) was 2.14%, indicating that our model offered statistically significant speech intelligibility improvements compared to all other systems.
- MERL's Speech & Audio team ranked 1st out of 12 teams in the 2nd COG-MHEAR Audio-Visual Speech Enhancement Challenge (AVSE). The team was led by Zexu Pan, and also included Gordon Wichern, Yoshiki Masuyama, Francois Germain, Sameer Khurana, Chiori Hori, and Jonathan Le Roux.
-
AWARD Joint CMU-MERL team wins DCASE2023 Challenge on Automated Audio Captioning Date: June 1, 2023
Awarded to: Shih-Lun Wu, Xuankai Chang, Gordon Wichern, Jee-weon Jung, Francois Germain, Jonathan Le Roux, Shinji Watanabe
MERL Contacts: François Germain; Jonathan Le Roux; Gordon Wichern
Research Areas: Artificial Intelligence, Machine Learning, Speech & AudioBrief- A joint team consisting of members of CMU Professor and MERL Alumn Shinji Watanabe's WavLab and members of MERL's Speech & Audio team ranked 1st out of 11 teams in the DCASE2023 Challenge's Task 6A "Automated Audio Captioning". The team was led by student Shih-Lun Wu and also featured Ph.D. candidate Xuankai Chang, Postdoctoral research associate Jee-weon Jung, Prof. Shinji Watanabe, and MERL researchers Gordon Wichern, Francois Germain, and Jonathan Le Roux.
The IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE Challenge), started in 2013, has been organized yearly since 2016, and gathers challenges on multiple tasks related to the detection, analysis, and generation of sound events. This year, the DCASE2023 Challenge received over 428 submissions from 123 teams across seven tasks.
The CMU-MERL team competed in the Task 6A track, Automated Audio Captioning, which aims at generating informative descriptions for various sounds from nature and/or human activities. The team's system made strong use of large pretrained models, namely a BEATs transformer as part of the audio encoder stack, an Instructor Transformer encoding ground-truth captions to derive an audio-text contrastive loss on the audio encoder, and ChatGPT to produce caption mix-ups (i.e., grammatical and compact combinations of two captions) which, together with the corresponding audio mixtures, increase not only the amount but also the complexity and diversity of the training data. The team's best submission obtained a SPIDEr-FL score of 0.327 on the hidden test set, largely outperforming the 2nd best team's 0.315.
- A joint team consisting of members of CMU Professor and MERL Alumn Shinji Watanabe's WavLab and members of MERL's Speech & Audio team ranked 1st out of 11 teams in the DCASE2023 Challenge's Task 6A "Automated Audio Captioning". The team was led by student Shih-Lun Wu and also featured Ph.D. candidate Xuankai Chang, Postdoctoral research associate Jee-weon Jung, Prof. Shinji Watanabe, and MERL researchers Gordon Wichern, Francois Germain, and Jonathan Le Roux.
-
-
Research Highlights
-
MERL Publications
- , "Factorized RVQ-GAN For Disentangled Speech Tokenization", Interspeech, August 2025.BibTeX TR2025-123 PDF
- @inproceedings{Khurana2025aug,
- author = {Khurana, Sameer and Klement, Dominik and Laurent, Antoine and Bobos, Dominik and Novosad, Juraj and Gazdik, Peter and Zhang, Ellen and Huang, Zilli and Hussein, Amir and Marxer, Ricard and Masuyama, Yoshiki and Aihara, Ryo and Hori, Chiori and Germain, François G and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{Factorized RVQ-GAN For Disentangled Speech Tokenization}},
- booktitle = {Interspeech},
- year = 2025,
- month = aug,
- url = {https://www.merl.com/publications/TR2025-123}
- }
- , "Investigating Continuous Autoregressive Generative Speech Enhancement", Interspeech, August 2025.BibTeX TR2025-119 PDF
- @inproceedings{Yang2025aug,
- author = {Yang, Haici and Wichern, Gordon and Aihara, Ryo and Masuyama, Yoshiki and Khurana, Sameer and Germain, François G and {Le Roux}, Jonathan},
- title = {{Investigating Continuous Autoregressive Generative Speech Enhancement}},
- booktitle = {Interspeech},
- year = 2025,
- month = aug,
- url = {https://www.merl.com/publications/TR2025-119}
- }
- , "HASRD: Hierarchical Acoustic and Semantic Representation Disentanglement", Interspeech, August 2025.BibTeX TR2025-122 PDF
- @inproceedings{Hussein2025aug,
- author = {Hussein, Amir and Khurana, Sameer and Wichern, Gordon and Germain, François G and {Le Roux}, Jonathan},
- title = {{HASRD: Hierarchical Acoustic and Semantic Representation Disentanglement}},
- booktitle = {Interspeech},
- year = 2025,
- month = aug,
- url = {https://www.merl.com/publications/TR2025-122}
- }
- , "Direction-Aware Neural Acoustic Fields for Few-Shot Interpolation of Ambisonic Impulse Responses", Interspeech, DOI: 10.21437/Interspeech.2025-1912, August 2025, pp. 933-937.BibTeX TR2025-120 PDF
- @inproceedings{Ick2025aug,
- author = {Ick, Christopher and Wichern, Gordon and Masuyama, Yoshiki and Germain, François G and {Le Roux}, Jonathan},
- title = {{Direction-Aware Neural Acoustic Fields for Few-Shot Interpolation of Ambisonic Impulse Responses}},
- booktitle = {Interspeech},
- year = 2025,
- pages = {933--937},
- month = aug,
- doi = {10.21437/Interspeech.2025-1912},
- url = {https://www.merl.com/publications/TR2025-120}
- }
- , "Exploring Disentangled Neural Speech Codecs from Self-Supervised Representations", arXiv, August 2025.BibTeX arXiv
- @article{Aihara2025aug,
- author = {Aihara, Ryo and Masuyama, Yoshiki and Germain, François G and Wichern, Gordon and {Le Roux}, Jonathan},
- title = {{Exploring Disentangled Neural Speech Codecs from Self-Supervised Representations}},
- journal = {arXiv},
- year = 2025,
- month = aug,
- url = {https://arxiv.org/abs/2508.08399}
- }
- , "Factorized RVQ-GAN For Disentangled Speech Tokenization", Interspeech, August 2025.
-
Other Publications
- , "Periodic Analysis of Nonlinear Virtual Analog Models", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), October 2021, pp. 321-325.BibTeX
- @Inproceedings{Germain:PeriodicAnalysisNonlinear:2021,
- author = {Germain, Fran\c{c}ois G.},
- title = {Periodic Analysis of Nonlinear Virtual Analog Models},
- booktitle = {{IEEE} Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
- year = 2021,
- pages = {321--325},
- month = oct
- }
- , "Practical Virtual Analog Modeling Using Möbius Transforms", International Conference on Digital Audio Effects (DAFx), September 2021, pp. 49-56.BibTeX
- @Inproceedings{Germain:PracticalVirtualAnalog:2021,
- author = {Germain, Fran\c{c}ois G.},
- title = {Practical Virtual Analog Modeling Using {M}\"{o}bius Transforms},
- booktitle = {International Conference on Digital Audio Effects (DAFx)},
- year = 2021,
- pages = {49--56},
- month = sep
- }
- , "Energy-preserving Time-varying Schroeder Allpass Filters and Multichannel Extensions", Journal of the Audio Engineering Society (AES), Vol. 69, No. 7/8, pp. 465-485, 2021.BibTeX
- @Article{WernerGermainGoldsmith:EnergypreservingTime:2021,
- author = {Werner, Kurt James and Germain, Francois G. and Goldsmith, Cory S.},
- title = {Energy-preserving Time-varying Schroeder Allpass Filters and Multichannel Extensions},
- journal = {Journal of the Audio Engineering Society (AES)},
- year = 2021,
- volume = 69,
- number = {7/8},
- pages = {465--485}
- }
- , "Non-oversampled Physical Modeling for Virtual Analog Simulations", 2019, Stanford University.BibTeX
- @Phdthesis{Germain:NonoversampledPhysical:2019,
- author = {Germain, Fran\c{c}ois G.},
- title = {Non-oversampled Physical Modeling for Virtual Analog Simulations},
- school = {{S}tanford University},
- year = 2019
- }
- , "Speech Denoising with Deep Feature Losses", INTERSPEECH Conference, September 2018, pp. 2723-2727.BibTeX
- @Inproceedings{GermainChenKoltun:SpeechDenoisingDeep:2018,
- author = {Germain, Francois G. and Chen, Qifeng and Koltun, Vladlen},
- title = {Speech Denoising with Deep Feature Losses},
- booktitle = {{INTERSPEECH} Conference},
- year = 2018,
- pages = {2723--2727},
- month = sep
- }
- , "Optimizing Differentiated Discretization for Audio Circuits beyond Driving Point Transfer Functions", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), October 2017, pp. 384-388.BibTeX
- @Inproceedings{GermainWerner:OptimizingDifferentiatedDiscretization:2017,
- author = {Germain, Fran\c{c}ois G. and Werner, Kurt James},
- title = {Optimizing Differentiated Discretization for Audio Circuits beyond Driving Point Transfer Functions},
- booktitle = {{IEEE} Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
- year = 2017,
- pages = {384--388},
- month = oct
- }
- , "Fixed-rate Modeling of Audio Lumped Systems: A Comparison between Trapezoidal and Implicit Midpoint Methods", International Conference on Digital Audio Effects (DAFx), September 2017, pp. 168-75.BibTeX
- @Inproceedings{Germain:FixedrateModeling:2017,
- author = {Germain, Fran\c{c}ois G.},
- title = {Fixed-rate Modeling of Audio Lumped Systems: A Comparison between Trapezoidal and Implicit Midpoint Methods},
- booktitle = {International Conference on Digital Audio Effects (DAFx)},
- year = 2017,
- pages = {168--75},
- month = sep
- }
- , "Network Variable Preserving Step-size Control in Wave Digital Filters", International Conference on Digital Audio Effects (DAFx), September 2017, pp. 200-207.BibTeX
- @Inproceedings{OlsenWernerGermain:NetworkVariablePreserving:2017,
- author = {Olsen, Michael J{\o}rgen and Werner, Kurt James and Germain, Fran{\c{c}}ois G.},
- title = {Network Variable Preserving Step-size Control in Wave Digital Filters},
- booktitle = {International Conference on Digital Audio Effects (DAFx)},
- year = 2017,
- pages = {200--207},
- month = sep
- }
- , "Joint Parameter Optimization of Differentiated Discretization Schemes for Audio Circuits", Audio Engineering Society (AES) Convention, May 2017.BibTeX
- @Inproceedings{GermainWerner:JointParameterOptimization:2017,
- author = {Germain, Fran\c{c}ois G. and Werner, Kurt James},
- title = {Joint Parameter Optimization of Differentiated Discretization Schemes for Audio Circuits},
- booktitle = {Audio Engineering Society (AES) Convention},
- year = 2017,
- month = may
- }
- , "A Computational Model of the Hammond Organ Vibrato/chorus Using Wave Digital Filters", International Conference on Digital Audio Effects (DAFx), September 2016, pp. 271-278.BibTeX
- @Inproceedings{WernerDunkelGermain:ComputationalModelHammond:2016,
- author = {Werner, Kurt James and Dunkel, W. Ross and Germain, Fran{\c{c}}ois G.},
- title = {A Computational Model of the Hammond Organ Vibrato/chorus Using Wave Digital Filters},
- booktitle = {International Conference on Digital Audio Effects (DAFx)},
- year = 2016,
- pages = {271--278},
- month = sep
- }
- , "Equalization Matching of Speech Recordings in Real-world Environments", IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), March 2016, pp. 609-613.BibTeX
- @Inproceedings{GermainMysoreFujioka:EqualizationMatchingSpeech:2016,
- author = {Germain, Fran\c{c}ois G. and Mysore, Gautham J. and Fujioka, Takako},
- title = {Equalization Matching of Speech Recordings in Real-world Environments},
- booktitle = {{IEEE} International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
- year = 2016,
- pages = {609--613},
- month = mar
- }
- , "Sinusoidal Parameter Estimation Using Quadratic Interpolation around Power-scaled Magnitude Spectrum Peaks", Applied Sciences, Vol. 6, No. 10, pp. 306, 2016.BibTeX
- @Article{WernerGermain:SinusoidalParameterEstimation:2016,
- author = {Werner, Kurt James and Germain, Fran{\c{c}}ois Georges},
- title = {Sinusoidal Parameter Estimation Using Quadratic Interpolation around Power-scaled Magnitude Spectrum Peaks},
- journal = {Applied Sciences},
- year = 2016,
- volume = 6,
- number = 10,
- pages = 306,
- publisher = {MDPI}
- }
- , "Design Principles for Lumped Model Discretization Using Möbius Transforms", International Conference on Digital Audio Effects (DAFx), December 2015, pp. 371-378.BibTeX
- @Inproceedings{GermainWerner:DesignPrinciplesLumped:2015,
- author = {Germain, Fran\c{c}ois G. and Werner, Kurt James},
- title = {Design Principles for Lumped Model Discretization Using {M}{\"o}bius Transforms},
- booktitle = {International Conference on Digital Audio Effects (DAFx)},
- year = 2015,
- pages = {371--378},
- month = dec
- }
- , "Speaker and Noise Independent Online Single-channel Speech Enhancement", IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), April 2015, pp. 71-75.BibTeX
- @Inproceedings{GermainMysore:SpeakerNoiseIndependent:2015,
- author = {Germain, Fran{\c{c}}ois G. and Mysore, Gautham J.},
- title = {Speaker and Noise Independent Online Single-channel Speech Enhancement},
- booktitle = {{IEEE} International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
- year = 2015,
- pages = {71--75},
- month = apr
- }
- , "Efficient Illuminant Correction in the Local, Linear, Learned (L3) Method", Digital Photography XI, February 2015, vol. 9404, pp. 24-30.BibTeX
- @Inproceedings{GermainAkinolaTianEtAl:EfficientIlluminantCorrection:2015,
- author = {Germain, Francois G. and Akinola, Iretiayo A. and Tian, Qiyuan and Lansel, Steven P. and Wandell, Brian A.},
- title = {Efficient Illuminant Correction in the Local, Linear, Learned ({L3}) Method},
- booktitle = {Digital Photography XI},
- year = 2015,
- volume = 9404,
- pages = {24--30},
- month = feb
- }
- , "Stopping Criteria for Non-negative Matrix Factorization Based Supervised and Semi-supervised Source Separation", IEEE Signal Processing Letters, Vol. 21, No. 10, pp. 1284-1288, 2014.BibTeX
- @Article{GermainMysore:StoppingCriteriaNon:2014,
- author = {Germain, Fran\c{c}ois G. and Mysore, Gautham J.},
- title = {Stopping Criteria for Non-negative Matrix Factorization Based Supervised and Semi-supervised Source Separation},
- journal = {{IEEE} Signal Processing Letters},
- year = 2014,
- volume = 21,
- number = 10,
- pages = {1284--1288},
- publisher = {IEEE}
- }
- , "Combining Modeling of Singing Voice and Background Music for Automatic Separation of Musical Mixtures", Internation Society for Music Information Retrieval (ISMIR) Conference, November 2013, pp. 41-46.BibTeX
- @Inproceedings{RafiiGermainSunEtAl:CombiningModelingSinging:2013,
- author = {Rafii, Zafar and Germain, Fran{\c{c}}ois G. and Sun, Dennis L. and Mysore, Gautham J.},
- title = {Combining Modeling of Singing Voice and Background Music for Automatic Separation of Musical Mixtures},
- booktitle = {Internation Society for Music Information Retrieval (ISMIR) Conference},
- year = 2013,
- pages = {41--46},
- month = nov
- }
- , "Speaker and Noise Independent Voice Activity Detection", INTERSPEECH Conference, August 2013, pp. 732-736.BibTeX
- @Inproceedings{GermainSunMysore:SpeakerNoiseIndependent:2013,
- author = {Germain, François G. and Sun, Dennis L. and Mysore, Gautham J.},
- title = {Speaker and Noise Independent Voice Activity Detection},
- booktitle = {{INTERSPEECH} Conference},
- year = 2013,
- pages = {732--736},
- month = aug
- }
- , "Uniform Noise Sequencers for Nonlinear System Identification", International Conference on Digital Audio Effects (DAFx), September 2012, pp. 241-244.BibTeX
- @Inproceedings{GermainAbelDepalleEtAl:UniformNoiseSequencers:2012,
- author = {Germain, Fran\c{c}ois G. and Abel, Jonathan S. and Depalle, Philippe and Wanderley, Marcelo M.},
- title = {Uniform Noise Sequencers for Nonlinear System Identification},
- booktitle = {International Conference on Digital Audio Effects (DAFx)},
- year = 2012,
- pages = {241--244},
- address = {York, United Kingdom},
- month = sep
- }
- , "A Nonlinear Analysis Framework for Electronic Synthesizer Circuits", October 2011, McGill University.BibTeX
- @Mastersthesis{Germain:NonlinearAnalysisFramework:2011,
- author = {Germain, Fran\c{c}ois Georges},
- title = {A Nonlinear Analysis Framework for Electronic Synthesizer Circuits},
- school = {McGill University},
- year = 2011,
- address = {Montr{\'e}al, Canada},
- month = oct
- }
- , "Acoustical Properties of the Vocal-tract in Trombone Performance", Forum Acusticum, June 2011, pp. 625-630.BibTeX
- @Inproceedings{FreourScavoneLefebvreEtAl:AcousticalPropertiesVocal:2011,
- author = {Freour, Vincent and Scavone, Gary P. and Lefebvre, Antoine and Germain, Fran{\c{c}}ois},
- title = {Acoustical Properties of the Vocal-tract in Trombone Performance},
- booktitle = {Forum Acusticum},
- year = 2011,
- pages = {625--630},
- month = jun
- }
- , "Synthesis of Guitar by Digital Waveguides: Modeling the Plectrum in the Physical Interaction of the Player with the Instrument", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), October 2009, pp. 25-28.BibTeX
- @Inproceedings{GermainEvangelista:SynthesisGuitarDigital:2009,
- author = {Germain, Fran{\c{c}}ois and Evangelista, Gianpaolo},
- title = {Synthesis of Guitar by Digital Waveguides: Modeling the Plectrum in the Physical Interaction of the Player with the Instrument},
- booktitle = {{IEEE} Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
- year = 2009,
- pages = {25--28},
- month = oct
- }
- , "Periodic Analysis of Nonlinear Virtual Analog Models", IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), October 2021, pp. 321-325.
-
Software & Data Downloads
-
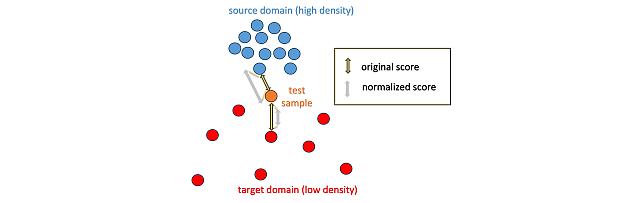
Local Density-Based Anomaly Score Normalization for Domain Generalization -
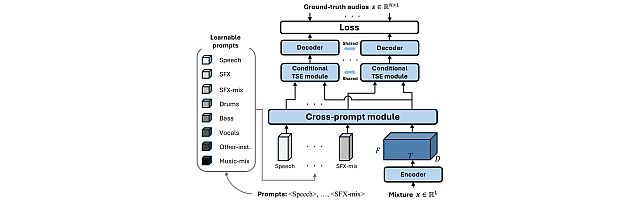
Task-Aware Unified Source Separation -
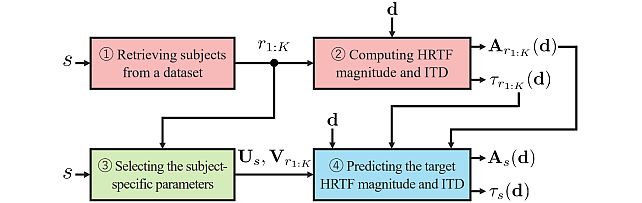
Retrieval-Augmented Neural Field for HRTF Upsampling and Personalization -
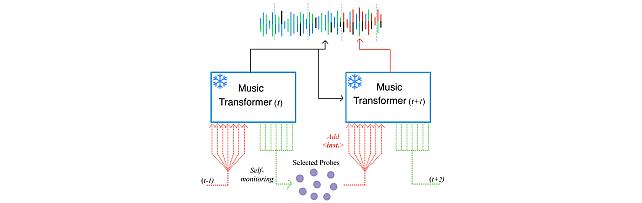
Self-Monitored Inference-Time INtervention for Generative Music Transformers -
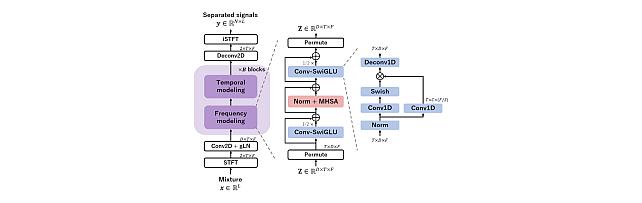
Transformer-based model with LOcal-modeling by COnvolution -
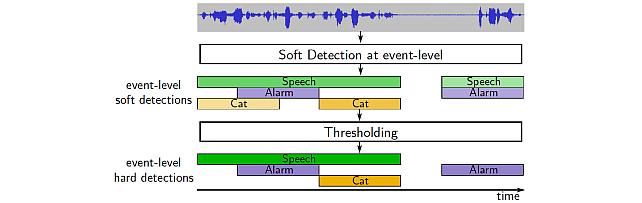
Sound Event Bounding Boxes -
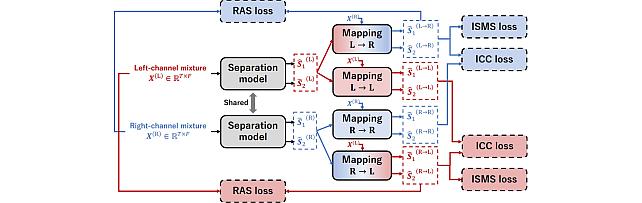
Enhanced Reverberation as Supervision -
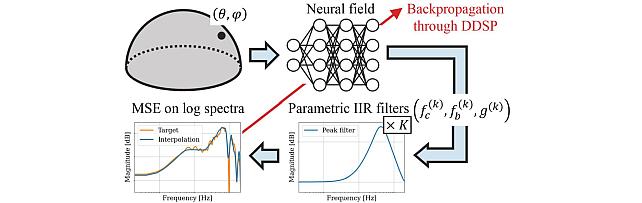
Neural IIR Filter Field for HRTF Upsampling and Personalization
-