TR2024-006
TS-SEP: Joint Diarization and Separation Conditioned on Estimated Speaker Embeddings
-
- , "TS-SEP: Joint Diarization and Separation Conditioned on Estimated Speaker Embeddings", IEEE/ACM Transactions on Audio, Speech, and Language Processing, DOI: 10.1109/TASLP.2024.3350887, Vol. 32, pp. 1185-1197, February 2024.BibTeX TR2024-006 PDF Software
- @article{Boeddeker2024feb,
- author = {Boeddeker, Christoph and Subramanian, Aswin Shanmugam and Wichern, Gordon and Haeb-Umbach, Reinhold and {Le Roux}, Jonathan},
- title = {{TS-SEP: Joint Diarization and Separation Conditioned on Estimated Speaker Embeddings}},
- journal = {IEEE/ACM Transactions on Audio, Speech, and Language Processing},
- year = 2024,
- volume = 32,
- pages = {1185--1197},
- month = feb,
- doi = {10.1109/TASLP.2024.3350887},
- issn = {2329-9304},
- url = {https://www.merl.com/publications/TR2024-006}
- }
- , "TS-SEP: Joint Diarization and Separation Conditioned on Estimated Speaker Embeddings", IEEE/ACM Transactions on Audio, Speech, and Language Processing, DOI: 10.1109/TASLP.2024.3350887, Vol. 32, pp. 1185-1197, February 2024.
-
MERL Contacts:
-
Research Areas:



Abstract:
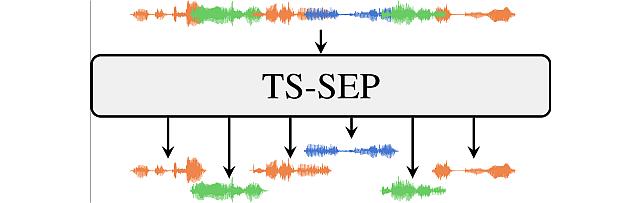
Since diarization and source separation of meeting data are closely related tasks, we here propose an approach to perform the two objectives jointly. It builds upon the target- speaker voice activity detection (TS-VAD) diarization approach, which assumes that initial speaker embeddings are available. We replace the final combined speaker activity estimation network of TS-VAD with a network that produces speaker activity estimates at a time-frequency resolution. Those act as masks for source extraction, either via masking or via beamforming. The technique can be applied both for single-channel and multi-channel input and, in both cases, achieves a new state-of-the-art word error rate (WER) on the LibriCSS meeting data recognition task. We further compute speaker-aware and speaker-agnostic WERs to isolate the contribution of diarization errors to the overall WER performance.
Software & Data Downloads
Related News & Events
-
EVENT MERL Contributes to ICASSP 2025 Date: Sunday, April 6, 2025 - , April 11, 2025
Location: Hyderabad, India
MERL Contacts: Wael H. Ali; Petros T. Boufounos; Radu Corcodel; Chiori Hori; Siddarth Jain; Toshiaki Koike-Akino; Jonathan Le Roux; Yanting Ma; Hassan Mansour; Yoshiki Masuyama; Joshua Rapp; Anthony Vetro; Pu (Perry) Wang; Gordon Wichern
Research Areas: Artificial Intelligence, Communications, Computational Sensing, Electronic and Photonic Devices, Machine Learning, Robotics, Signal Processing, Speech & AudioBrief- MERL has made numerous contributions to both the organization and technical program of ICASSP 2025, which is being held in Hyderabad, India from April 6-11, 2025.
Sponsorship
MERL is proud to be a Silver Patron of the conference and will participate in the student job fair on Thursday, April 10. Please join this session to learn more about employment opportunities at MERL, including openings for research scientists, post-docs, and interns.
MERL is pleased to be the sponsor of two IEEE Awards that will be presented at the conference. We congratulate Prof. Björn Erik Ottersten, the recipient of the 2025 IEEE Fourier Award for Signal Processing, and Prof. Shrikanth Narayanan, the recipient of the 2025 IEEE James L. Flanagan Speech and Audio Processing Award. Both awards will be presented in-person at ICASSP by Anthony Vetro, MERL President & CEO.
Technical Program
MERL is presenting 15 papers in the main conference on a wide range of topics including source separation, sound event detection, sound anomaly detection, speaker diarization, music generation, robot action generation from video, indoor airflow imaging, WiFi sensing, Doppler single-photon Lidar, optical coherence tomography, and radar imaging. Another paper on spatial audio will be presented at the Generative Data Augmentation for Real-World Signal Processing Applications (GenDA) Satellite Workshop.
MERL Researchers Petros Boufounos and Hassan Mansour will present a Tutorial on “Computational Methods in Radar Imaging” in the afternoon of Monday, April 7.
Petros Boufounos will also be giving an industry talk on Thursday April 10 at 12pm, on “A Physics-Informed Approach to Sensing".
About ICASSP
ICASSP is the flagship conference of the IEEE Signal Processing Society, and the world's largest and most comprehensive technical conference focused on the research advances and latest technological development in signal and information processing. The event has been attracting more than 4000 participants each year.
- MERL has made numerous contributions to both the organization and technical program of ICASSP 2025, which is being held in Hyderabad, India from April 6-11, 2025.
Related Publication
- @article{Boeddeker2023mar,
- author = {Boeddeker, Christoph and Subramanian, Aswin Shanmugam and Wichern, Gordon and Haeb-Umbach, Reinhold and {Le Roux}, Jonathan},
- title = {{TS-SEP: Joint Diarization and Separation Conditioned on Estimated Speaker Embeddings}},
- journal = {arXiv},
- year = 2023,
- month = mar,
- url = {https://arxiv.org/abs/2303.03849}
- }